RAPIDS - Sciences des données accélérées par GPU
Cette page permet de mettre en avant la solution accélérée par GPU RAPIDS (NVIDIA) pour tous travaux de sciences des données et Big Data : analyse de données, visualisation de données, modélisation de données, apprentissage machine (random forest, PCA, arbres gradient boostés, k-means,...). Sur Jean Zay, il suffira de charger le module correspondant pour utiliser RAPIDS, par exemple :
module load rapids/24.04
La solution la plus adaptée pour une étude de données avec RAPIDS sur Jean Zay est d'ouvrir un notebook en interactif sur un nœud de calcul via une instance JupyterHub.
Sur un nœud de calcul Jean Zay, il n'y a pas d'accès internet. Toute installation de librairie ou tout téléchargement de données devra se faire avant la réservation de ressources sur le nœud de calcul.
À la fin de cette page vous trouverez un lien vers des notebooks d'exemples de fonctionnalités RAPIDS.
Cette documentation se limite à l'utilisation de RAPIDS sur un seul nœud (mono-GPU et multi-GPU).
Accélération GPU
L'utilisation de RAPIDS et des GPU devient intéressante par rapport aux solutions classiques sur CPU lorsque le tableau de données manipulé atteint plusieurs gigaoctets en mémoire. Dans ce cas, l'accélération de la plupart des tâches de lecture/écriture, de prétraitement des données, d'apprentissage machine est notable.
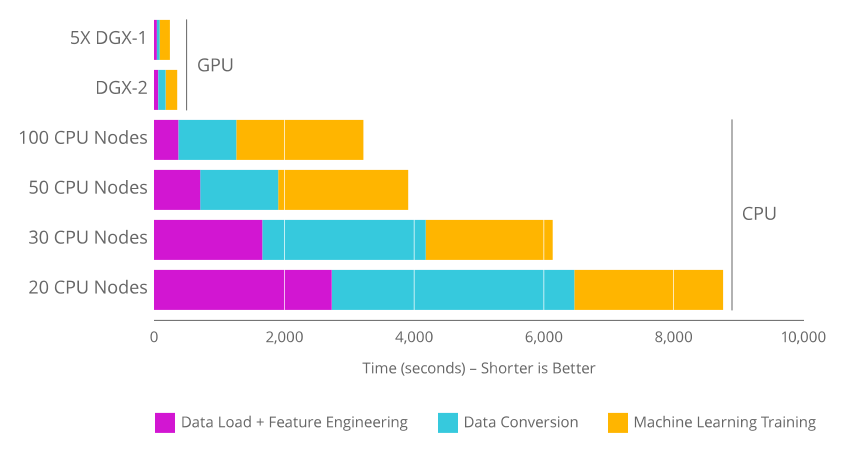
Illustration issue de la documentation RAPIDS de l'accélération GPU pour un dataset de 400 Go (DGX-2 = 16 GPU V100)
Les API RAPIDS optimisent l'utilisation des GPU pour les travaux d'analyse de données et d'apprentissage machine. Le portage du code python est simple à réaliser : toutes les API RAPIDS reproduisent les fonctionnalités des API de référence dans le traitement par CPU.

Diagramme de facilité d'utilisation versus la performance en fonction du niveau de proximité à l'architecture GPU.
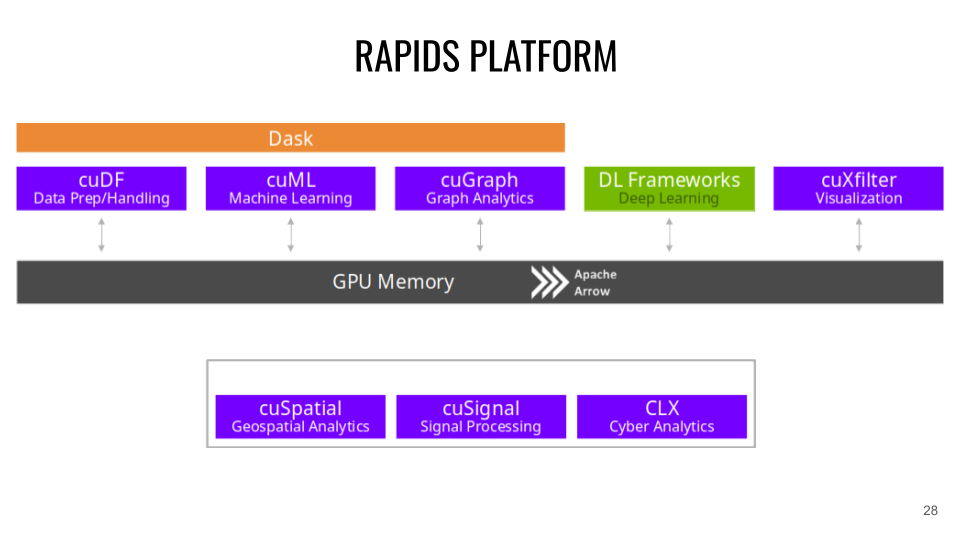
Plateforme et API RAPIDS
RAPIDS se base sur Apache Arrow qui prend en charge la gestion du stockage en mémoire des structures de données.
-
CuDF (correspondance CPU : Pandas ). CuDF est une librairie de DataFrames GPU pour le chargement des données, pour les opérations de fusion, d'agrégation, de filtrage et autres manipulations de données. Exemple :
import cudftips_df = cudf.read_csv('dataset.csv')tips_df['tip_percentage'] = tips_df['tip'] / tips_df['total_bill'] * 100# display average tip by dining party sizeprint(tips_df.groupby('size').tip_percentage.mean()) -
CuML (correspondance CPU : scikit-learn ). CuML est une librairie d'algorithme de Machine Learning sur données tabulaires compatible avec les autres API RAPIDS et l'API scikit-learn (XGBOOST peut aussi directement s'utiliser sur les API RAPIDS). Exemple :
import cudffrom cuml.cluster import DBSCAN# Create and populate a GPU DataFramegdf_float = cudf.DataFrame()gdf_float['0'] = [1.0, 2.0, 5.0]gdf_float['1'] = [4.0, 2.0, 1.0]gdf_float['2'] = [4.0, 2.0, 1.0]# Setup and fit clustersdbscan_float = DBSCAN(eps=1.0, min_samples=1)dbscan_float.fit(gdf_float)print(dbscan_float.labels_) -
CuGraph (correspondance CPU : NetworkX ). CuGraph est une librairie d'analyse de Graph qui prendra en entrée une Dataframe GPU. Exemple :
import cugraph# read data into a cuDF DataFrame using read_csvgdf = cudf.read_csv("graph_data.csv", names=["src", "dst"], dtype=["int32", "int32"])# We now have data as edge pairs# create a Graph using the source (src) and destination (dst) vertex pairsG = cugraph.Graph()G.from_cudf_edgelist(gdf, source='src', destination='dst')# Let's now get the PageRank score of each vertex by calling cugraph.pagerankdf_page = cugraph.pagerank(G)# Let's look at the PageRank Score (only do this on small graphs)for i in range(len(df_page)):print("vertex " + str(df_page['vertex'].iloc[i]) +" PageRank is " + str(df_page['pagerank'].iloc[i])) -
Cuxfilter (correspondance CPU : Bokeh / Datashader ). Cuxfilter est une librairie de visualisation de données. Elle permet de connecter un crossfiltering accéléré par GPU à une représentation web.
-
CuSpatial (correspondance CPU : GeoPandas / SciPy.spatial ). Cuspatial est une librairie de traitement de données spatiales incluant les polygones de point, les jonctions spatiales, les systèmes de coordonnées géographiques, les formes primitives, les distances et les analyses de trajectoire.
-
CuSignal (correspondance CPU : SciPy.signal). Cusignal est une librairie de traitement du signal.
-
CLX (correspondance CPU : cyberPandas ). CLX est une librairie de traitement et d'analyse de données de cybersécurité.
Accélération Multi-GPU avec Dask-CUDA
La librairie Dask-CUDA permet d'utiliser les principales API RAPIDS sur plusieurs GPU au sein d'un Cluster Dask. Cela permet d'accélérer votre code et surtout de pouvoir traiter des tableaux de données de plusieurs dizaines ou centaines de gigaoctets, ce qui saturerait la mémoire RAM d'un seul GPU.
Pour configurer un Cluster Dask qui exploite tous les GPU d'un nœud :
from dask.distributed import Client
from dask_cuda import LocalCUDACluster
cluster = LocalCUDACluster()
client = Client(cluster)
Il est possible d'utiliser des Clusters Dask en multi-nœuds avec Slurm mais la mise en place est complexe et n'est pas abordée ici.
Dask fonctionne sur un principe de workflow. Les commandes à exécuter sont dans un premier temps organisées par Dask au sein d'un graphe computationnel. Leur exécution est déclenchée dans un second temps à l'appel de la fonction .compute().
import dask_cudf
ddf = dask_cudf.read_csv('x.csv')
mean_age = ddf['age'].mean()
mean_age.compute()
Par défaut, le résultat obtenu est concaténé et stocké dans la mémoire d'un seul GPU (celui correspondant au processus "client" du Cluster). Si des calculs successifs sont prévus, il est possible de conserver le résultat en mémoire sur chaque GPU afin d'éviter des transferts inutiles. Cela se fait grâce à la commande .persist() :
ddf = dask_cudf.read_csv('x.csv')
ddf = ddf.persist()
ddf['age'].mean().compute()
Exemple avec cuML :
from dask.distributed import Client
from dask_cuda import LocalCUDACluster
import dask_cudf
import cuml
from cuml.dask.cluster import KMeans
cluster = LocalCUDACluster()
client = Client(cluster)
ddf = dask_cudf.read_csv('x.csv').persist()
dkm = KMeans(n_clusters=20)
dkm.fit(ddf)
cluster_centers = dkm.cluster_centers_
cluster_centers.columns = ddf.column
labels_predicted = dkm.predict(ddf)
class_idx = cluster_centers.nsmallest(1, 'class1').index[0]
labels_predicted[labels_predicted==class_idx].compute()
Notebooks d'exemple sur Jean Zay
Vous trouverez des notebooks d'exemple (cuml, xgboost, cugraph, cusignal, cuxfilter, clx) dans les conteneurs de démonstration de RAPIDS.
Ces notebooks sont mis à disposition sur Jean Zay. Pour les copier dans votre espace personnel, il faudra exécuter la commande suivante :
cp -r $DSDIR/examples_IA/Rapids $WORK