Débuter sur le supercalculateur
Introduction
Vous débutez au supercalculateur Jean Zay ?
Sur cette page vous trouverez les principaux points indispensables pour accéder à Jean Zay, faire votre première connexion et soumettre votre premier travail.
Cette page s'adresse principalement aux nouveaux·elles utilisateurs·rices de l'IDRIS. Elle est voulue synthétique pour assurer une prise en main rapide du supercalculateur. Pour plus d'informations sur les différents points abordés, n’hésitez pas à consulter la documentation complète.
Et pour un aperçu rapide des commandes Linux, Module et SLURM utiles pour les utilisateurs·rices de Jean Zay, consulter la cheatsheet ci-dessus.
Vous avez une question ou une demande ?
Le Support Utilisateurs de l’IDRIS est joignable,
du lundi au jeudi de 9h à 18h et le vendredi de 9h à 17h30 :
📥 assist@idris.fr
☎️ +33 (0)1 69 35 85 55
Présentation de la machine Jean Zay
Jean Zay est un supercalculateur composé de cinq partitions :
-
une partition scalaire (nœuds équipés uniquement de CPU)
-
et quatre partitions accélérées (nœuds hybrides équipés à la fois de CPU et de GPU).
L'ensemble des nœuds accède à un système de fichiers partagés via un réseau d'interconnexion à très forte bande passante.
Une description matérielle complète est disponible sur la page Le supercalculateur Jean Zay.
Voici un aperçu de l'architecture de la machine :
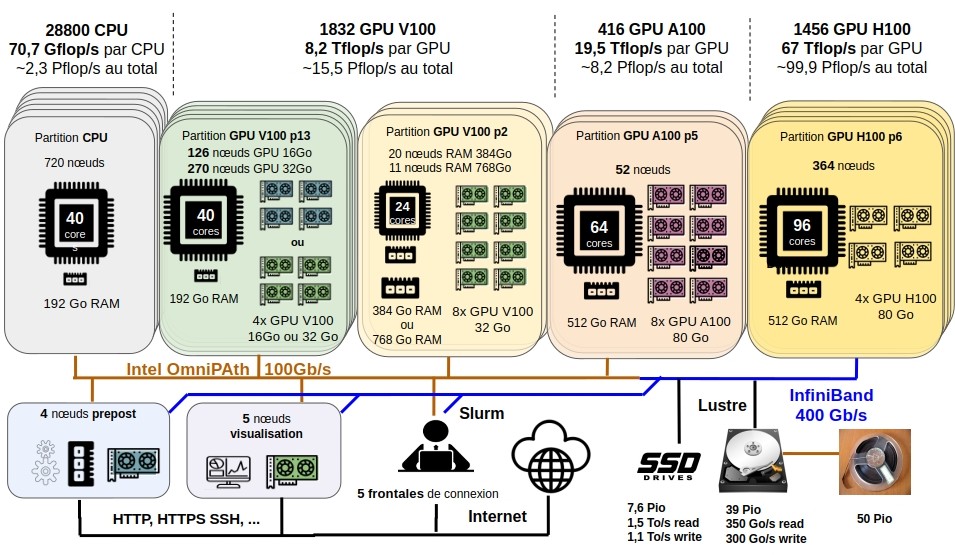
Tous les projets DARI ayant des heures CPU ou/et GPU ont à leur disposition des partitions de calcul définies sur Jean Zay. Elles permettent aux utilisateurs·rices de choisir le type de ressource (CPU ou GPU) qu'ils désirent utiliser. Le tableau ci-dessous récapitule les principales caractéristiques de ces partitions.
| Partition | Nom | Nb CPU par nœud | RAM CPU | Nb GPU par nœud | RAM GPU |
|---|---|---|---|---|---|
| CPU | cpu_p1 | 40 | 192 Go | - | - |
| quadri-GPU V100 | p13 | 40 | 192 Go | 4 | 16 Go / 32 Go |
| octo-GPU V100 | p2 | 24 | 384 Go / 768 Go | 8 | 32 Go |
| octo-GPU A100 | p5 | 64 | 512 Go | 8 | 80Go |
| quadri-GPU H100 | p6 | 96 | 512 Go | 4 | 80Go |
-
Pour plus d'informations sur les différentes partitions, consultez les pages concernant les Partitions Slurm CPU ou/et les Partitions Slurm GPU.
-
Tous les projets ayant des heures CPU ou/et GPU ont également accès à des partitions dédiées au pré et post traitement, à la visualisation, à la compilation ou à l'archivage. Sur ces partitions les heures de calcul ne sont pas déduites de votre allocation. Pour plus d´informations sur ces partitions, consultez la page Partitions Slurm CPU.
Accéder au supercalculateur
Toute demande d'ouverture de compte sur la machine Jean Zay se fait sur le portail eDARI.
Cette demande implique une demande de rattachement à un projet scientifique ayant des heures de calcul sur le supercalculateur. Vous pouvez donc joindre un projet existant avec l'accord de son chef de projet ou créer votre projet. La création d'un projet scientifique se fait via une demande d'heures de calcul sur le portail eDARI.
Avant tout, nous vous recommandons de consulter la note GENCI détaillant les modalités d'accès aux ressources nationales. Vous y trouverez entre autres, les conditions et critères d’éligibilité pour obtenir des heures de calcul et un compte sur les supercalculateurs.
C'est l'opérateur public GENCI (Grand équipement national de calcul intensif), qui gère l'attribution des ressources de calcul de l'ensemble des centres nationaux (CINES, IDRIS et TGCC).
Pour calculer sur Jean Zay :
Pour pouvoir calculer sur Jean Zay, vous devrez réaliser les trois étapes suivantes :
- Créer un compte utilisateur sur eDARI
- Demander une allocation d'heures de calcul (sauf si rattachement à un projet existant)
- Demander la création d'un compte utilisateur Jean Zay (avec rattachement à un projet)
- 1. Compte utilisateur eDARI
- 2. Allocation d'heures de calcul
- 3. Compte utilisateur Jean Zay
Créer un compte utilisateur sur eDARI
Il faut tout d´abord créer un compte utilisateur sur https://www.edari.fr/user/login en utilisant votre adresse mail institutionnelle.
Ce compte est uniquement destiné à accéder à votre espace personnel sur le site eDARI pour réaliser toutes les démarches administratives (demandes d'heures de calcul, ouvertures de comptes sur Jean Zay, ...) qui doivent être effectuées depuis le eDARI. Il n'a aucun lien avec votre éventuel compte utilisateur Jean Zay.
Vous trouverez plus d'informations sur les demandes d'heures et les demandes d'ouverture de compte sur Jean Zay dans la vidéo suivante :
Demande l'allocation d'heures de calcul
Il existe deux types d’accès aux ressources selon le nombre d’heures demandées :
- l'accès régulier et
- l'accès dynamique.
Les principales différences entre eux sont résumées ci-dessous :
| Accès Réguliers (AR) | Accès Dynamiques (AD) |
|---|---|
| ≥ 500k heures CPU ≥ 50k heures GPU normalisées∗ | < 500k heures CPU < 50k heures GPU normalisées∗ |
| Deux sessions d’allocation par an : - en mai (dépôt du dossier avant févr.) - en nov. (dépôt du dossier avant sept.) | Ouverts toute l’année : la validation d’un AD prend quelques jours |
| Expertises technique et scientifique | Pas d’expertise |
(∗) 50k heures GPU normalisées = 50k heures V100 ou 25k heures A100 ou 12,5k heures H100.
Pour de plus amples informations sur la demande et les différents types d'accès, consultez la page concernant Les demandes d'heures.
Demander la création d'un compte de calcul
Il n'y a pas d'ouverture de compte automatique ou implicite. Il faut donc aussi demander l'ouverture d'un compte de calcul (compte utilisateur Jean Zay). Cette demande se fait également via eDARI pour Jean Zay.
Les informations fournies sont automatiquement transmises à notre service de gestion administrative des utilisateurs·rices (gestutil@idris.fr) pour le suivi de votre demande coté IDRIS. Vous pourrez être contacté par ce service si votre situation nécessite de plus amples informations et/ou des démarches supplémentaires pour la création de votre compte de calcul.
Pour de plus amples informations sur les demandes de création des comptes de calcul, consultez la page Ouverture / Fermeture de compte.
Toute machine utilisée pour accéder au calculateur de l'IDRIS via le protocole SSH doit être enregistrée dans les filtres de l'IDRIS. Pour cela, tout·e utilisateur·rice doit fournir, lors de la demande de création de compte, la liste des machines avec lesquelles il se connectera au calculateur de l'IDRIS (voir Déclaration des machines de connexion.)
Pour effectuer des modifications sur un compte existant (p.ex. modifier les adresses IP de connexion, réinitialiser votre mot de passe etc.), veuillez remplir le Formulaire FGC.
Connexion
Première connexion via ssh
La première connexion à Jean Zay doit se faire en SSH, depuis une adresse institutionnelle enregistrée dans les filtres de l'IDRIS et associée à votre compte de calcul :
ssh login@jean-zay.idris.fr
Pour votre première connexion, vous devez utiliser votre mot de passe initial constitué de la concaténation
- du mot de passe généré aléatoirement par l'IDRIS (envoyée par courriel)
- et du mot de passe que vous avez renseigné lors de votre demande d'ouverture de compte (eDARI).
Ce mot de passe sera changé immédiatement à la première connexion (procédure automatique) afin de définir votre mot de passe courant. Vous trouverez un exemple de première connexion dans Gestion des mots de passe.
- A la première connexion, le mot de passe initial est demandé deux fois (une fois pour la connexion et une seconde fois pour le changement du mot de passe initial).
- Le fait d'être immédiatement déconnecté après que le nouveau mot de passe choisi ait été accepté (
all authentication tokens updated successfully) est normal.
Une fois connecté(e), vous arrivez sur l'une des 5 frontales (nœuds de connexion) de Jean Zay. Ces nœuds, partagés par l’ensemble des utilisateurs·rices, sont dédiés à la mise en place de l’environnement de calcul et ne doivent pas être utilisés pour effectuer des calculs (ils ne sont pas équipés de GPU).
Contrairement aux nœuds de calcul, les frontales disposent d’un proxy HTTP/HTTPS permettant de télécharger des données depuis des serveurs distants (via le protocole HTTP/HTTPS avec les commandes git ou wget par exemple).
Pour plus d'informations concernant la connexion sur Jean Zay (cibler une frontale spécifique, les connexions ssh par clef ou avec certificat etc.), consultez la page Accès SSH et shells.
Connexion via JupyterHub
Les équipes de l’IDRIS ont mis en place une solution JupyterHub permettant d’utiliser les Jupyter Notebooks et d’autres applications comme VSCode, MLflow ou Dask via une interface web sans connexion SSH préalable à la machine.
Une première connexion à Jean Zay en SSH est indispensable avant de pouvoir utiliser JupyterHub.
Gestion de vos données
Les espaces disques
Chaque utilisateur dispose d'un espace personnel HOME (unique même pour les utilisateurs rattachés à plusieurs projet).
De plus, pour chaque projet auquel l'utilisateur participe, 4 espaces disques avec des caractéristiques diverses sont accessibles : WORK, SCRATCH, STORE et DSDIR.
Pour stocker vos fichiers prenez soin de bien choisir le meilleur espace disque en fonction de leurs caractéristiques respectives. Cela est indispensable pour éviter de saturer vos quotas (calculs qui échouent) ou la perte de données (espace disque automatiquement purgé).
Le tableau ci-dessous récapitule leurs principales caractéristiques. Pour savoir plus sur comment mieux utiliser vos espaces disques, consultez la page Espaces Disques.
| Espace Disque | Capacité par défaut | Usage | Commande |
|---|---|---|---|
| $HOME | Quotas 3 Go / 150k inodes par utilisateur | - répertoire d'accueil lors d'une connexion interactive - destiné aux fichiers de petite taille (p.ex. fichiers de configuration) - unique dans le cas d'un login multi-projets | cd $HOME |
| $WORK | Quotas 5 To / 500k inodes par projet * | - espace de travail et de stockage permanent - prévu pour accueillir des fichiers de taille importante (p.ex. données d'entrée/sortie) | Partie propre à chaque utilisateur :cd $WORK Partie commune et accessible par tous les utilisateurs du projet : cd $ALL_CCFRWORK |
| $SCRATCH | Quotas de sécurité très larges 4,6 Po partagés par tous les utilisateurs | - espace de travail et de stockage semi-temporaire - Durée de vie des fichiers non lus ou modifiés : 30 jours - Performances optimales pour les opérations de lecture/écriture | Partie propre à chaque utilisateur :cd $SCRATCH Partie commune et accessible par tous les utilisateurs du projet : cd $ALL_CCFRSCRATCH |
| $STORE | Quotas 50 To / 100k inodes par projet * | - espace d'archivage - accessible depuis les frontales et les partitions prepost, archive, compil et visu | Partie propre à chaque utilisateur :cd $STORE Partie commune et accessible par tous les utilisateurs du projet : cd $ALL_CCFRSTORE |
| $DSDIR | - | - espace visible par tous les utilisateurs de Jean Zay - contient des modèles et des bases de données publiques volumineuses - mis en place par les équipes de l'IDRIS - uniquement en lecture | cd $DSDIR |
* les quotas par projet peuvent être augmentés sur demande du chef de projet ou de son suppléant via l'interface Extranet ou sur demande auprès du support utilisateurs.
💡 Les quotas disque
Vous pouvez consulter l'occupation de vos espaces disques en utilisant l'une de ces deux commandes :
idr_quota_userpour une vue de votre utilisation personnelle en tant qu'utilisateur·rice ;idr_quota_projectpour une vue d'ensemble de votre projet et de la consommation de chacun de ses membres.
Pour plus d'informations, consultez la page concernant Les Quotas disques et la visualisation des taux d'occupation.
💡 Les bonnes pratiques pour la gestion des bases de données
- Afin d'éviter de saturer vos espaces disques, pensez à vérifier si le modèle ou la base de données dont vous avez besoin ne se trouve pas déjà sur DSDIR.
- Si le téléchargement est nécessaire (base de données non publique) et que sa volumétrie vous impose de la télécharger dans votre SCRATCH (quotas très larges), conservez une copie de votre base de données sous forme d'archives dans le STORE (le SCRATCH est un espace semi-permanent). Vous pourrez ainsi facilement restaurer votre base de données si des fichiers ont été supprimés.
- WORK ou SCRATCH ?
- WORK : Vos fichiers ne sont soumis à aucune procédure de suppression automatique, mais les performances en lecture et écriture sont moins bonnes que celles du SCRATCH. Les quotas sont aussi plus restreints.
- SCRATCH : Quotas très larges et meilleures performances en lecture et écriture. Mais, les fichiers non accédés depuis 30 jours sont automatiquement supprimés !
- Si vous travaillez sur une base de données publique, nous pouvons la télécharger pour vous dans l'espace disque partagé DSDIR. Les données seront alors accessibles à l'ensemble des utilisateurs·rices.
- Pour plus d'informations sur les bonnes pratiques concernant la gestion de vos données, consultez la page Bases de données.
Transférer des données entre votre machine de connexion et Jean Zay
Si vous avez besoin de transférer des données entre votre machine et Jean Zay, vous pouvez utiliser les commandes liées à ssh (sftp et scp).
# Envoi d’un fichier local vers Jean Zay
scp localSource login@jean-zay.idris.fr:JZDestination
# Récupération d’un fichier de Jean Zay vers la machine locale
scp login@jean-zay.idris.fr:JZSource localDestination
ou
# Connexion au serveur distant via SFTP
sftp login@jean-zay.idris.fr destination
# Envoi d’un fichier local vers Jean Zay
sftp> put localSource JZDestination
# Récupération d’un fichier depuis Jean Zay vers la machine locale
sftp> get JZSource localDestination
Pour que cela fonctionne, il faut que votre machine soit enregistrée dans les filtres IDRIS ou que vous passiez par une machine enregistrée !
Pour plus d'informations sur comment transférer des données en batch, consultez la page Transférer des données entre l'IDRIS et votre machine de connexion et cette cheatsheet.
Environnement de calcul
L’IDRIS met à disposition un catalogue d’outils (environnements virtuels, librairies compilées,...) accessibles via la commande module.
La commande module
Afin de charger les produits installés sur Jean Zay, il est nécessaire d'utiliser la commande module. Le tableau suivant récapitule les commandes module de base.
| Action | Commande module |
|---|---|
| afficher les modules contenant le paquet demandé | idr_module_search <package> |
| afficher le catalogue complet | module avail |
| rechercher un outil précis | module avail <package> |
| obtenir des infos sur un module | module show <package> |
| charger un module | module load <package>/<version> |
| décharger un module | module unload <package> |
| afficher la liste des modules chargés | module list |
| repartir d’un environnement vierge | module purge |
Pour accéder aux modules adaptés à la partition A100 ou H100, il faut charger au préalable l'un des modulefiles suivants :
- Pour la partition A100 :
module load arch/a100 - Pour la partition H100 :
module load arch/h100
- La liste des modules peut être enrichie sur demande en contactant l'assistance via assist@idris.fr.
- Pour plus d'informations sur l'utilisation de la commande
module, consultez la page Modules
Modules et environnements virtuels conda
Des environnement virtuels conda préinstallés par l'IDRIS sont accessibles via la commande module.
- L’environnement est activé automatiquement (
conda activate) lors du chargement du module (module load conda). - ATTENTION, il n’est pas désactivé (
conda deactivate) lorsque le module est déchargé (module unload conda).
Une fois l’environnement activé, vous pouvez visualiser l’ensemble des paquets Python qu’il contient grâce aux commandes pip list et conda list.
- Il est fortement conseillé d’utiliser les environnements installés par nos soins pour obtenir les meilleures performances, mutualiser les ressources et éviter de saturer vos quotas.
- Tout environnement peut être enrichi sur demande en contactant l'assistance via assist@idris.fr.
Modules et compilation
Différents compilateurs et bibliothèques sont disponibles sur Jean Zay ( module avail ) et sont activables au moyen de la commande module load.
Nous vous recommandons fortement de consulter notre page Web concernant l'utilisation de la commande module et la gestion des dépendances entre les versions des bibliothèques et celles des compilateurs.
Pour plus d'informations sur la compilation et les différents compilateurs disponibles, consultez les pages dédiées.
Soumission de travaux
Deux modes de travail sont possibles :
- en batch
- en interactif
Le travail en batch permet de fermer la session interactive après avoir soumis un travail, tandis que le travail en interactif nécessite de maintenir la session ouverte pour ne pas interrompre l’exécution.
Il est fortement déconseillé de faire des calculs sur les nœuds de connexion car cela peut les ralentir (voir les faire crasher) ce qui impacterait tous les autres utilisateurs connectés sur le même nœud !
De plus, les limites fixées sur ces nœuds (1 CPU par utilisateur et 30 mn de temps CPU par processus) ne permettent pas d'obtenir de bonnes performances.
Pour plus d'informations sur ces deux modes de travail, consultez les pages Exécution en batch et Exécution interactive.
Vous trouverez ci-dessous des exemples pour une prise en main rapide.
Exécution en batch - Exemple de script SLURM
L’accès aux ressources de calcul est géré par le gestionnaire Slurm pour l’ensemble des utilisateurs·rices.
Il y a 2 étapes essentielles pour travailler en batch :
- La création du script Slurm : fichier contenant les directives Slurm pour la réservation des ressources et les commandes à exécuter.
- la soumission du travail (job) : le script Slurm est soumis au gestionnaire via les commandes Slurm
sbatchousrunpour son exécution sur les ressources demandées.
L'accès aux diverses partitions hardware de la machine dépend du type de travail soumis (CPU ou GPU) et de la partition Slurm demandée pour son exécution (Voir Partitions Slurm CPU et Partitions Slurm GPU pour plus d'informations).
- Le mode batch ne permet pas à l’utilisateur·rice d’intervenir au cours de l'exécution des commandes du script (sauf pour interrompre le déroulement du job). Par conséquent, les transferts de fichiers doivent s'effectuer sans avoir à taper de mot de passe.
- Les nœuds de calcul n'ont aucun accès à Internet ce qui interdit tout téléchargement (dépôts Git, installation Python/Conda, …) depuis ces nœuds. Si besoin, les téléchargements doivent être effectués depuis les frontales ou depuis les nœuds de pré / post-traitement avant l'exécution du code : soit en interactif, soit via la soumission batch de travaux en cascade.
Ci-dessous, vous trouverez des exemples de scripts pour l'exécution d'un code MPI en HPC et d'un script Python en IA :
- Exemple HPC
- Exemple IA
Voici un exemple de script de soumission CPU pour un travail MPI en batch sur Jean Zay :
1. Contenu du fichier intel_mpi.slurm :
#!/bin/bash
#SBATCH --job-name=TravailMPI # nom du job
#SBATCH --ntasks=80 # Nombre total de processus MPI
#SBATCH --ntasks-per-node=40 # Nombre de processus MPI par noeud
# /!\ Attention, la ligne suivante est trompeuse mais dans le vocabulaire
# de Slurm "multithread" fait bien référence à l'hyperthreading.
#SBATCH --hint=nomultithread # 1 processus MPI par coeur physique (pas d'hyperthreading)
#SBATCH --time=00:10:00 # Temps d’exécution maximum demande (HH:MM:SS)
#SBATCH --output=TravailMPI%j.out # Nom du fichier de sortie
#SBATCH --error=TravailMPI%j.out # Nom du fichier d'erreur (ici commun avec la sortie)
# on se place dans le répertoire de soumission
cd ${SLURM_SUBMIT_DIR}
# nettoyage des modules charges en interactif et herites par defaut
module purge
# chargement des modules
module load intel-all/19.0.4
# echo des commandes lancées
set -x
# exécution du code
srun ./exec_mpi
2. Soumission du script via la commande sbatch :
sbatch intel_mpi.slurm
Pour plus d'informations sur l'exécution de travaux, y compris différents exemples (MPI, OpenMP, MPMD, CUDA MPS), consultez la page dédiée.
Voici un exemple de script pour une exécution sur la partition octo-GPU A100 :
1. Dans le fichier gpu_a100.slurm :
#!/bin/bash
#SBATCH --job-name=TravailGPU # nom du job
#SBATCH --output=TravailGPU%j.out # fichier de sortie (%j = job ID)
#SBATCH --error=TravailGPU%j.err # fichier d’erreur (%j = job ID)
#SBATCH --constraint=a100 # demander des GPU A100 80 Go
#SBATCH --nodes=2 # reserver 2 nœuds
#SBATCH --ntasks=16 # reserver 16 taches (ou processus)
#SBATCH --gres=gpu:8 # reserver 8 GPU par noeud
#SBATCH --cpus-per-task=8 # reserver 8 CPU par tache (et la memoire associee)
#SBATCH --time=20:00:00 # temps maximal d’allocation "(HH:MM:SS)"
# #SBATCH --qos=qos_gpu_a100-t3 # QoS (par défaut donc commentee)
#SBATCH --hint=nomultithread # desactiver l’hyperthreading
#SBATCH --account=xyz@a100 # comptabilite A100 (xyz a remplace par
le groupe unix du projet)
module purge # nettoyer les modules herites par defaut
conda deactivate # desactiver les environnements herites par defaut
module load arch/a100 # selectionner les modules compiles pour les A100
module load pytorch-gpu/py3/2.3.0 # charger les modules
set -x # activer l’echo des commandes
srun python script.py # executer son script
Le tableau ci-dessous récapitule les options SLURM à utiliser pour sélectionner une partition hardware en particulier :
| Partition GPU | Option SLURM correspondante |
|---|---|
| quadri-GPU V100 avec 16 ou 32 Go RAM | par défaut (sans option) |
| quadri-GPU V100 avec 16 Go RAM | --constraint v100-16g |
| quadri-GPU V100 avec 32 Go RAM | --constraint v100-32g |
| octo-GPU V100 (avec CPU 384Go ou 768Go RAM) | --partition=gpu_p2 |
| octo-GPU V100 (avec CPU 384Go RAM) | --partition=gpu_p2s |
| octo-GPU V100 (avec CPU 768Go RAM) | --partition=gpu_p2l |
| octo-GPU A100 | --constraint=a100 |
| quadri-GPU H100 | --constraint=h100 |
Dans l'exemple ci-dessus, on demande deux nœuds de la partition gpu_p5 (nœuds octo-GPU A100).
#SBATCH --constraint=a100: Sélectionne les nœuds octo-GPU A100.

Chacun de ces deux nœuds nous donne accès à :
- 8 GPU NVIDIA A100 avec 80 Go de mémoire
- 64 cœurs CPU
- 512 Go de mémoire RAM
-
#SBATCH --nodes=2: Permet de réserver deux nœuds de la même partition. -
#SBATCH --ntasks=16: Le nombre total de tâches/processus reservés qui sont répartis sur les 2 nœuds.
Il est souvent égal au nombre total de GPU reservés car on attribue généralement 1 GPU par tâches/processus.
-
#SBATCH --gres=gpu:8: Le nombre de GPU reservés par nœud. Soit 16 GPU au total car on reserve 2 nœuds. -
#SBATCH --cpus-per-task=8: Le nombre de cœurs CPU reservés par tâche. Ici, il y aura 8 tâches par nœud (16/2) donc on reserve 8x8=64 CPU par nœud (soit la totalité des CPU donc de la mémoire de chaque nœud).
Il est recommandé de réserver la même proportion de ressources par nœud pour les CPU que pour les GPU. Ceci évitera d'avoir une surfacturation lors du décompte des heures de calcul utilisées par le travail (voir Visualisation de la consommation d'heures de calcul).
Le tableau suivant récapitule les proportions idéales par nœud suivant la partition utilisée :
| Partition | Nombre de GPU | Nombre de CPU |
|---|---|---|
| gpu_p13 | 1 V100 | 10 cœurs CPU |
| gpu_p2 | 1 V100 | 3 cœurs CPU |
| gpu_p5 | 1 A100 | 8 cœurs CPU |
| gpu_p6 | 1 H100 | 24 cœurs CPU |
-
#SBATCH --time=20:00:00: Temps maximal d’exécution. Les limites maximales de temps sont fonction de la partition et de la QoS utilisées (voir QoS ci-dessous). -
#SBATCH --qos=qos_gpu_a100-t3: Pour chaque job soumis sur une partition de calcul (donc autre que archive, compil, prepost et visu), vous pouvez spécifier une QoS (Quality of Service) qui va déterminer les limites et la priorité de votre job. Il existe 3 différents types de QoS :- QoS dev : réservées à des exécutions brèves (max. 2h) effectuées dans le cadre de développement
- QoS t3 : QoS par défaut (max. 20h)
- QoS t4 : pour des exécutions plus longues (max. 100h)
TIPChaque QoS attribue une priorité différente à votre job. Pour des tests courts (moins de 2 heures), privilégiez la QoS dev.
INFOPour plus d'informations sur les QoS, les différentes limites définies par chacune d'elles et les différentes commandes pour les spécifier selon la partition, consultez la page dédiée.
-
#SBATCH --hint=nomultithread: Désactive l'hyperthreading, forçant l’utilisation d’un seul thread par cœur physique (utilisation des cœurs réels et pas de threads logiques). -
#SBATCH --account=xyz@a100: Spécifie la comptabilité (accounting) pour le décompte des heures. Le projet doit avoir une allocation A100 pour utiliser les GPU A100. Ici xyz doit être remplacé par le groupe unix du projet.
Pour plus d'informations sur la comptabilité des heures, consultez la page Heures de calcul.
set -x: Active l'affichage des commandes exécutées. Chaque commande sera consignée dans les logs.
2. Soumission du script Slurm
Lorsque les directives de soumission sont définies, il est recommandé d'entrer les commandes dans l'ordre suivant :
- se placer dans le répertoire d'exécution WORK, SCRATCH ou JOBSCRATCH ;
- copier les fichiers d’entrée nécessaires à l’exécution ;
- lancer l'exécution avec
sbatch a100.slurm; - éventuellement copier les fichiers de résultats que vous souhaitez conserver si vous avez utilisé le SCRATCH ou le JOBSCRATCH
Suivre l'avancement d'un job SLURM
Le tableau suivant récapitule les principales commandes pour soumettre le script SLURM et suivre son avancement.
| Commande | Fonction |
|---|---|
sbatch <script> | soumettre un script batch Slurm |
squeue -u $USER | suivre l’état de soumission de vos jobs |
scontrol show job <jobid> | afficher l’ensemble des paramètres d’un job soumis |
scancel <jobid> | annuler l’exécution d’un job |
Vous pouvez vous connecter en SSH aux nœuds de calcul affectés à vos travaux afin de surveiller en direct l’exécution de vos calculs et contrôler l'usage des ressources ( top, htop, nvidia-smi,...) : ssh <numéro du nœud>
Exécution en interactif
Toute exécution en mode interactif nécessite de réserver des ressources via le gestionnaire Slurm. Le temps d'attribution de ces ressources varie suivant la charge de la machine.
Il est impossible de prévoir le moment auquel les ressources demandées seront attribuées. Si vous n'êtes pas devant votre machine à cet instant, des ressources seront réservées à votre usage sans que vous les utilisiez.
A partir de machines déclarées dans les filtres de l'IDRIS, vous disposez d'un accès SSH aux frontales. Vous avez alors 2 possibilités :
- Ouvrir un terminal directement sur un nœud de calcul sur lequel vous réservez des ressources via la commande
srun.- Exemple avec réservation d’un GPU pour 1h00 sur la partition par défaut :
login@jean-zay3:∼$ srun --ntasks=1 --gres=gpu:1 --time=1:00:00 ... --pty bashsrun: job 123456 queued and waiting for resourcessrun: job 123456 has been allocated resourceslogin@r13i0n8:∼$- Vous êtes alors connecté sur le nœud de calcul et pouvez exécuter votre code/script :
login@r13i0n8:∼$ ./script.py- Pour se déconnecter :
login@r13i0n8:∼$ exitexitlogin@jean-zay3:∼$ATTENTION- MPI n’est pas supporté dans cette configuration.
- Lorsque la limite de temps (ici 1h00) est atteinte la connexion au nœud de calcul est automatiquement coupée. L'exécution est donc interrompue prématurément.
- Faire une allocation de ressources via la commande
sallocet enchaîner des exécutions sur ces ressources via la commandesrun.- Exemple avec réservation d’un GPU pour 1h00 de la partition par défaut :
login@jean-zay1:∼$ salloc --ntasks=1 --gres=gpu:1 <other-options>salloc: Pending job allocation 654321salloc: job 654321 queued and waiting for resourcessalloc: job 654321 has been allocated resourcessalloc: Granted job allocation 654321- Lorsque l'allocation est effective, vous pouvez enchaîner diverses exécutions :
login@jean-zay1:∼$ srun python script_0.py...login@jean-zay1:∼$ srun python script_1.py...- Pour libérer les ressources :
login@jean-zay1:∼$ exitexitlogin@jean-zay1:∼$ salloc: Relinquishing job allocation 654321ATTENTION- Lorsque la limite de temps (ici 1h00) est atteinte l'allocation du nœud de calcul est automatiquement terminée. Toute exécution en cours est donc interrompue prématurément.
Pour plus d'informations sur l'exécution en interactif, consultez la page dédiée..
Pour aller plus loin
Formations
L’IDRIS dispense diverses formations à destination des utilisateurs·rices de calcul scientifique HPC et IA.
Contactez l'IDRIS
Pour toute question ou demande le Support Utilisateurs de l’IDRIS est joignable, du lundi au jeudi de 9h à 18h et le vendredi de 9h à 17h30 :
- 📥 assist@idris.fr
- ☎️ +33 (0)1 69 35 85 55
Workshops
L’IDRIS organise des workshops autour de la prise en main du supercalculateur et de l’optimisation de vos codes de calcul.
- 👨🏽💻 Workshop Jean Zay