Profilage d'applications PyTorch
Nous présentons ici comment instrumenter son code PyTorch avec le profiler intégré dans la librairie et différentes manières de visualiser les traces générées.
Instrumenter un code PyTorch pour le profilage
Dans le code PyTorch, il faut tout d'abord importer et définir le type de monitoring souhaité lors de la définition du profiler :
from torch.profiler import profile, tensorboard_trace_handler, ProfilerActivity, schedule
prof = profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], # 1
schedule=schedule(wait=1, warmup=1, active=12, repeat=1), # 2
on_trace_ready=tensorboard_trace_handler(logname), # 3
profile_memory=True, # 4
record_shapes=False, # 5
with_stack=False, # 6
with_flops=False) # 7
où :
- activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA] : permet de monitorer à la fois l'activité CPU et GPU ;
- schedule=[...] : permet de définir un cycle de profilage. On ignore généralement la première step qui n'est pas représentative (
wait=1), on définit un temps supplémentaire pour l'initialisation des outils CUDA de monitoring (warmup=1), on monitore quelques steps seulement (ici 12 steps avecactive=12) et on définit combien de fois le cycle doit se répéter (une seule fois ici avecrepeat=1) ; - on_trace_ready=tensorboard_trace_handler(logname) : permet de stocker les logs dans un format json compatible avec le plugin TensorBoard ;
- profile_memory=True : permet de récupérer les traces mémoire ;
- record_shapes=True : permet de récupérer le format des tenseurs en entrées des fonctions ;
- with_stack=True : permet de conserver la call stack ;
- with_flops : permet de récupérer une estimation des performances FLOPs des opérations sur les tenseurs.
- Le profilage est une opération coûteuse, on ne l'effectue en général que sur quelques steps seulement.
- Conserver la call stack avec
with_stack=Trueaugmente significativement la tailles des logs.
Il faut ensuite invoquer le profiler au début de la boucle d'apprentissage et indiquer la fin de la step en appelant prof.step() :
with prof:
for epoch in range(args.epochs):
for i, (samples, labels) in enumerate(train_loader):
...
prof.step() # Need to call this at the end of each step to notify profiler of steps' boundary.
Il est possible de personnaliser le profilage en intégrant des décorateurs record_function autour des zones d'intérêt. Par exemple :
from torch.profiler import profile, record_function, ProfilerActivity
...
with profile(activities=[ProfilerActivity.CPU, ProfilerActivity.CUDA], record_shapes=True) as prof:
with record_function("Training loop"):
train()
...
def train():
for epoch in range(1, num_epochs+1):
for i_step in range(1, total_step+1):
# Obtain the batch.
with record_function("Loading input batch"):
images, captions = next(iter(data_loader))
...
with record_function("Training step"):
...
loss = criterion(outputs.view(-1, vocab_size), captions.view(-1))
...
Visualisation des traces
Visualisation basique
On peut demander l'affichage d'un tableau récapitulatif des traces de profiling à la fin du script en ajoutant la ligne suivante :
print(prof.key_averages().table(sort_by="cpu_time", row_limit=10))
avec :
sort_bypermettant de trier les fonctions par catégorie (par exemple :<device>_time,self_<device>_time_total,<device>_time_total,self_<device>_memory_usage,<device>_memory_usage) ;row_limit=Npermettant de limiter l'affichage aux N premières fonctions.
On obtient une liste des fonctions balisées automatiquement ou par nos soins (via les décorateurs) triée dans l'ordre souhaité. Par exemple :
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg CPU Mem Self CPU Mem CUDA Mem Self CUDA Mem # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
ProfilerStep* 30.66% 434.580ms 75.83% 1.075s 89.576ms 0.000us 0.00% 398.617ms 33.218ms 0 B -8 B 99.24 MB -39.20 GB 12
DistributedDataParallel.forward 4.68% 66.296ms 21.15% 299.826ms 24.986ms 0.000us 0.00% 328.890ms 27.408ms 0 B 0 B 39.87 GB -2.71 GB 12
aten::item 0.01% 123.548us 16.79% 238.018ms 9.917ms 0.000us 0.00% 37.216us 1.551us 0 B 0 B 0 B 0 B 24
aten::_local_scalar_dense 0.04% 512.303us 16.78% 237.895ms 9.912ms 37.216us 0.00% 37.216us 1.551us 0 B 0 B 0 B 0 B 24
cudaStreamSynchronize 16.69% 236.618ms 16.70% 236.786ms 9.866ms 0.000us 0.00% 0.000us 0.000us 0 B 0 B 0 B 0 B 24
Runtime Triggered Module Loading 2.08% 29.521ms 2.08% 29.521ms 7.380ms 1.415ms 0.15% 1.415ms 353.807us 0 B 0 B 0 B 0 B 4
Optimizer.step#SGD.step 0.99% 14.036ms 4.78% 67.830ms 5.653ms 0.000us 0.00% 15.416ms 1.285ms 0 B 0 B 99.61 MB 0 B 12
aten::_foreach_mul_ 0.47% 6.731ms 1.32% 18.778ms 1.707ms 3.337ms 0.36% 4.255ms 386.783us 0 B 0 B 0 B 0 B 11
aten::_foreach_add_ 0.70% 9.947ms 2.06% 29.251ms 1.272ms 9.423ms 1.01% 10.628ms 462.097us 0 B 0 B 0 B 0 B 23
Activity Buffer Request 0.08% 1.106ms 0.08% 1.106ms 1.106ms 1.152us 0.00% 1.152us 1.152us 0 B 0 B 0 B 0 B 1
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 1.418s
Self CUDA time total: 935.789ms
Plugin TensorBoard
Les traces générées par le profiler PyTorch peuvent être visualisées avec le plugin TensorBoard torch_tb_profiler.
Le plugin torch_tb_profiler reste exploitable mais n'est plus maintenu. Les utilisateur·ices sont officiellement renvoyé·es vers l'utilisation alternative de la librairie HTA mais celle-ci n'offre pas les mêmes fonctionnalités.
La visualisation des traces est possible sur la plateforme JupyterHub de l'IDRIS, en ouvrant TensorBoard selon la procédure décrite dans cette page.
Vous pouvez également ouvrir les traces sur votre machine locale si vous le souhaitez. Il faut au préalable avoir installé le plugin : pip install torch_tb_profiler. TensorBoard s'ouvre ensuite comme d'habitude : tensorboard --logdir <profiler log directory>.
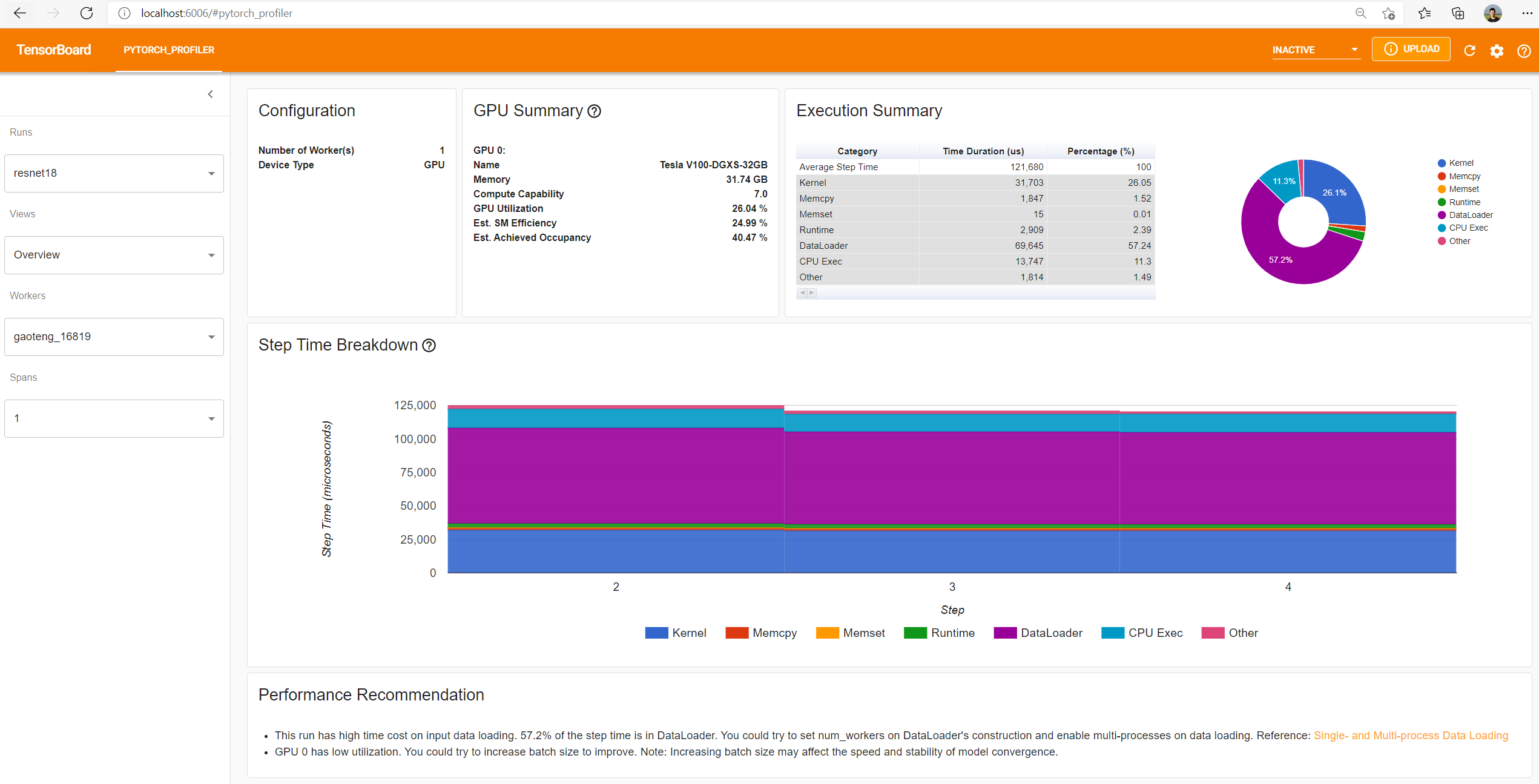
Dans l'onglet PYTORCH_PROFILER, vous trouverez alors différentes vues :
- Overview
- Operator view
- Kernel view
- Trace view
- Memory view, si l'option
profile_memorya été activée dans le code Python - Distributed view, si le code est distribué sur plusieurs GPU
Onglet Overview
Onglet Distributed view
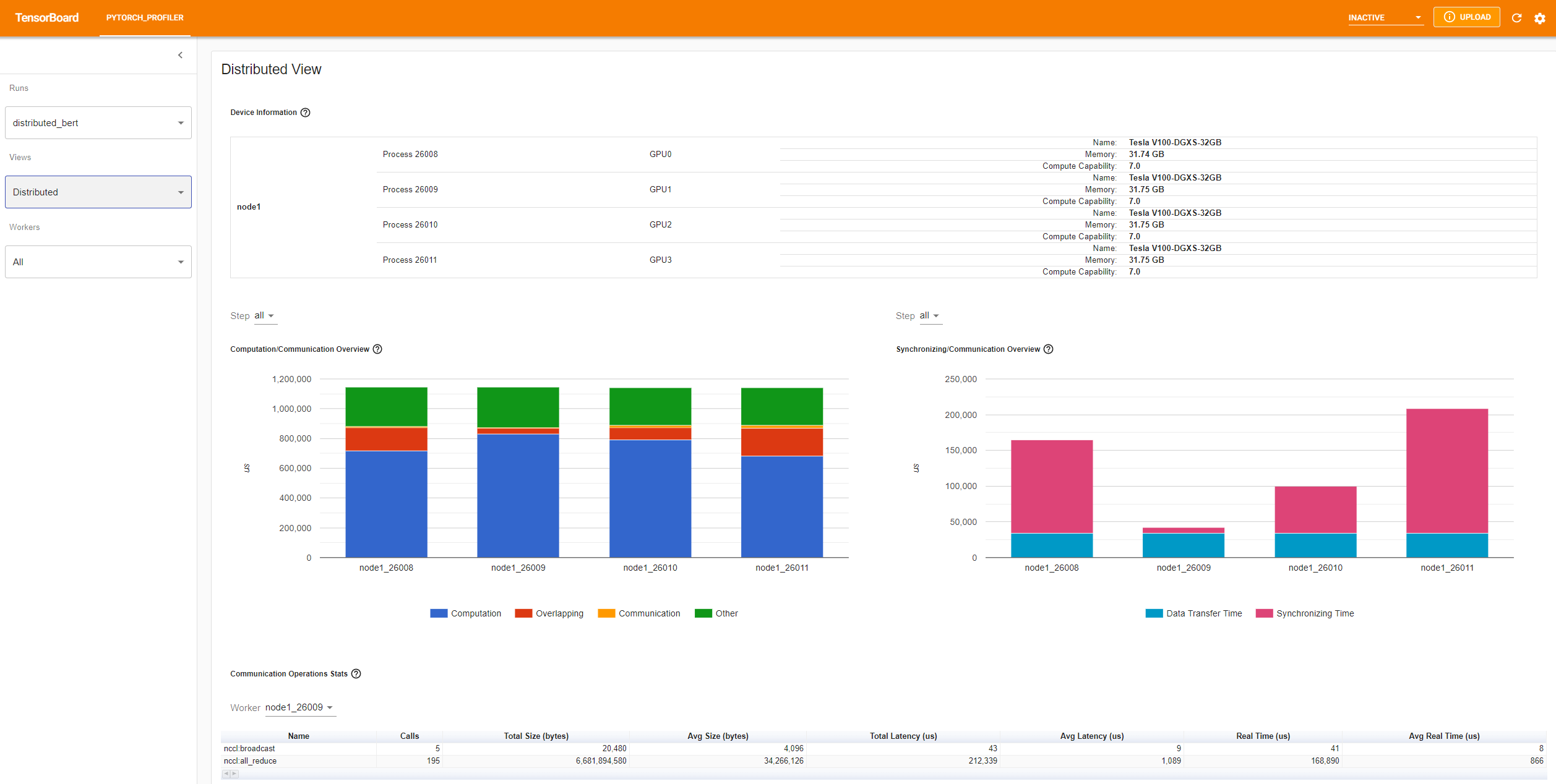
Depuis pytorch 1.10.0 des informations sur l'utilisation des Tensor Cores sont présentes sur Overview, Operator view et Kernel View.
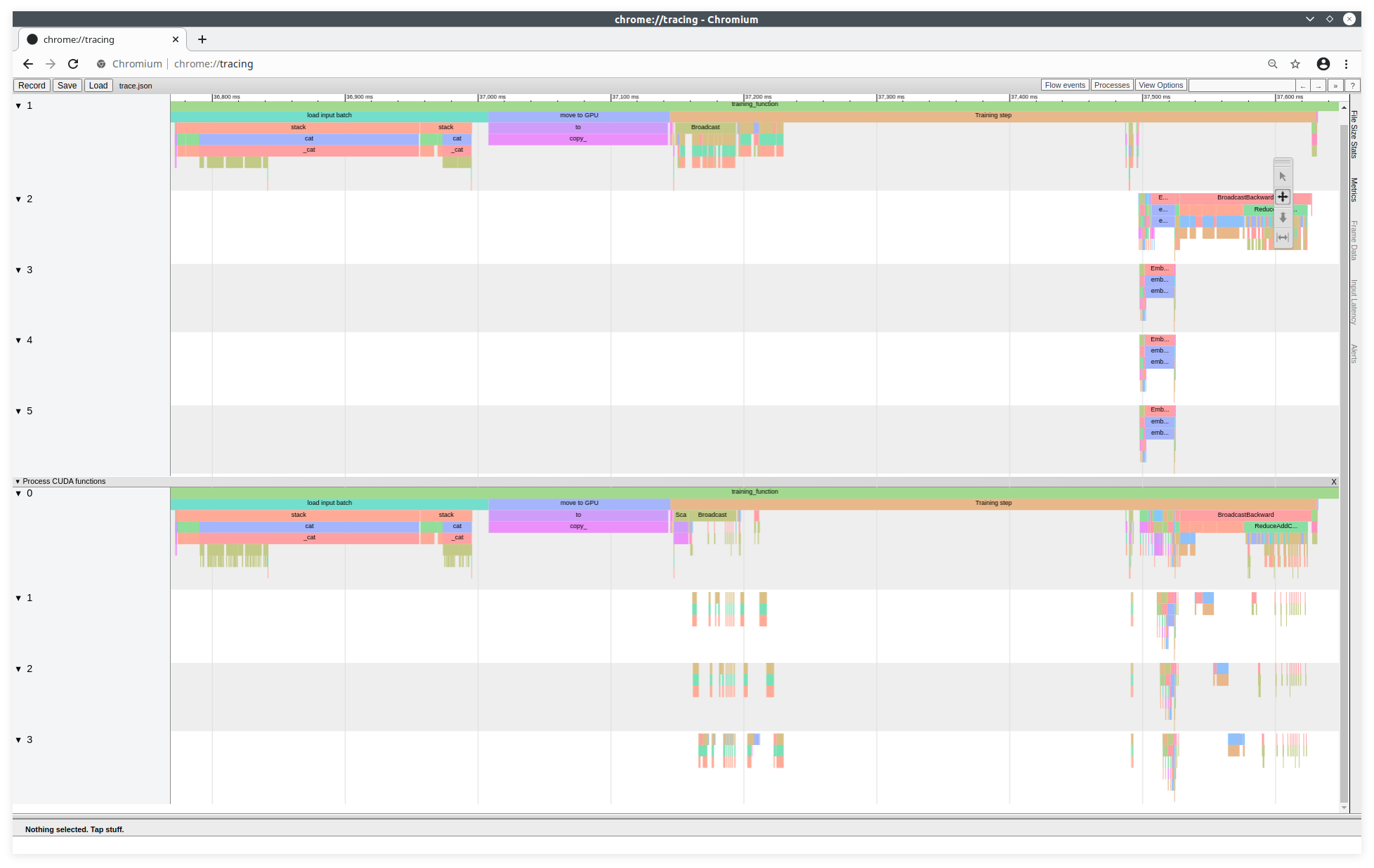
Chromium tracing
Pour afficher un Trace Viewer équivalent à celui de TensorBoard, vous pouvez également générer un fichier de trace json avec la ligne suivante :
prof.export_chrome_trace("trace.json")
Ce fichier de trace est visualisable sur l'outil de trace du projet Chromium. À partir d'un navigateur CHROME (ou CHROMIUM), il faut lancer la commande suivante dans la barre URL:
about:tracing
Exemple de trace de l'outil Chromium