Profilage de codes Python
Nous présentons ici des techniques pour suivre spécifiquement l'évolution de la mémoire CPU et la durée des instructions lors de l'exécution d'un script Python.
Les méthodes proposées sont faciles à mettre en œuvre et possèdent chacune des points forts.
Récapitulatif
Voici un récapitulatif des spécificités de chacune :
| type | informations | Impact vitesse | Limites | |
|---|---|---|---|---|
| CEEMS | Mémoire, CPU, GPU, consommation électrique, émissions de CO2, flame graph | Suit l'utilisation mémoire, CPU et GPU, peut afficher la trace de l'utilisation mémoire, effectué automatiquement pour les jobs Slurm | Les résultats sont disponibles uniquement pour les jobs de plus de 5 minutes. | |
| Scalene | Mémoire, CPU, GPU | Profilage complet ou par fonction via décorateur, vue très complète sous forme de tableau (CPU, mémoire, GPU possible) | ++ | Provoque des CUDA Out Of Memory Error lorsqu'utilisé avec des workers PyTorch. |
| Memory Profiler | Mémoire | Profilage complet ou par fonction via décorateur, vue agrégée | +++ | Le profilage ligne-par-ligne de processus parallèles peut mélanger la sortie de chaque processus. |
| Fil profiler | Mémoire max | Profilage mémoire générant un flame graph pour trouver l'instruction provoquant un pic d'allocation | + | |
| py-spy | flame graph, call stack, suivi en temps réel | Package Python permettant de surveiller en temps réel un processus Python et ses sous-processus | ||
| Nsight Systems | Mémoire, CPU, GPU | Un outil NVIDIA permettant d'afficher l'utilisation mémoire (CPU & GPU) et la trace d'exécution précise du code lancé | ? | |
| Investigation manuelle | Mémoire, CPU | Deux codes Python qui permettent de ponctuellement observer une fonction (durée) ou une structure (mémoire) |
L'outil le plus complet est CEEMS, qui récupère les informations de consommation énergétique et d'utilisation mémoire des jobs directement depuis les capteurs intégrés au matériel.
CEEMS ne prend en compte que les jobs dont la durée dépasse 5 minutes.
Nsight Systems est un outil NVIDIA capable de profiler l'ensemble d'un code et d'afficher l'utilisation des CPU, GPU et mémoire tout au long de l'exécution via une interface graphique, ainsi que d'identifier des opportunités d'amélioration du code.
L'outil Scalene génère un fichier donnant des informations exhaustives, ligne par ligne du code ainsi profilé (CPU, mémoire, GPU, nombre d'appels). Il a aussi l'avantage de ne pas trop ralentir l'exécution (+33% constatés sur une expérimentation de traitement de données).
L'outil Memory Profiler se distingue en proposant une vue graphique de l'occupation mémoire au cours du temps :
- ligne par ligne comme pour Scalene mais une fonction appelée plusieurs fois apparaît (avec son contenu) autant de fois qu'il y a d'appels ;
- l'affichage graphique permet de facilement voir les pics et les éventuelles fuites mémoire (il est normalement possible d'annoter les fonctions appelées sur ce graphe mais cela ne semble pas fonctionnel pour l'instant).
Ces deux outils Scalene et Memory Profiler nécessitent d'appeler le code via un exécutable (respectivement scalene et mprof) et/ou d'ajouter des lignes de code (un import et des décorateurs).
Le module Fil profiler est le plus limité en terme de fonctionnalités mais il peut être intéressant si vous êtes habitué aux visualisations graphiques des appels de fonctions dans un code.
L'outil py-spy offre la possibilité de suivre en temps réel l'exécution de son processus Python. Il peut créer une trace du pic mémoire ou sortir le callstack en temps réel de tous les threads et sous-threads du processus. Très utile pour identifier des threads bloquants.
- Faites le profilage en réservant un nœud de calcul dynamiquement via
srunplutôt que via un job lancé parsbatch. Attention au délai d'attente pour obtenir les ressources de calcul qui varie en fonction de la charge de la machine ! - Ne gardez pas le profilage actif si vous n'êtes plus en train d'expérimenter pour préserver votre quota d'heures de calcul !
- Vérifiez les dernières versions des bibliothèques et les nouveautés.
- Essayez de mettre les parties du code à profiler sous forme de fonctions ou de classes (pour l'usage de décorateur).
- Il arrive que les profilers génèrent des fichiers core, n'oubliez pas de les effacer car ils peuvent être très volumineux.
- Attention, si vous avez un out of memory lors d'une session dynamique sur un nœud de calcul, vous n'en serez informé que lorsque vous quitterez cette session et non lorsque le programme exécuté échouera !
Mise en place d'outils Python
Si des outils ne sont pas disponibles dans les modules qui vous intéressent :
- vous pouvez demander leurs installations à l'assistance (assist@idris.fr) en précisant le module que vous utilisez ;
- ou vous pouvez les installer vous même en surchargeant un module existant (
pytorch-gpu/py3/2.6.0dans cet exemple) avec l'une des commandes pip suivantes :
module load pytorch-gpu/py3/2.6.0
pip install --upgrade --user --no-cache-dir memory_profiler
pip install --upgrade --user --no-cache-dir filprofiler
pip install --upgrade --user --no-cache-dir scalene
pip install --upgrade --user --no-cache-dir py-spy
Certains de ces profilers sont activement développés, il peut donc être avantageux de les réinstaller avec l'option pip --upgrade même si des versions sont déjà disponibles dans les modules, pour pouvoir bénéficier des dernières fonctionnalités et corrections d'erreur.
Pour utiliser les exécutables de ces outils (quand ils existent), il est nécessaire de modifier la variable PATH avant leurs appels :
-
Par défaut, les installations se font dans votre HOME donc utilisez la commande suivante :
export PATH=$HOME/.local/bin:$PATH -
Mais si vous avez redéfini la variable PYTHONUSERBASE c'est cette variable qu'il faut utiliser :
export PATH=$PYTHONUSERBASE/bin:$PATH
CEEMS
Il est possible d'accéder au relevé énergétique pour chacun de ses projets (pour chaque partition matérielle) ainsi qu'à l'utilisation CPU et GPU moyenne de ses jobs.
Le dashboard par défaut de CEEMS

En cliquant sur un job listé, on accède ensuite à un résumé spécifique à ce job avec, entre autre, la consommation énergétique et une estimation des émissions de CO2. CEEMS permet également de visualiser les utilisations mémoire, CPU et GPU au cours du temps.
Les graphes d'utilisation CPU et GPU d'un job sur CEEMS

Enfin, en précisant export CEEMS_ENABLE_PROFILING=1 dans le fichier Slurm, CEEMS va imprimer la trace du job.
La trace mémoire CEEMS d'un job slurm

Une documentation supplémentaire est disponible sur la page dédiée.
Scalene
Pour cet outil, le code est exécuté via la commande scalene plutôt que python :
- Par exemple, pour une sortie au format texte dans le terminal, utilisez la commande suivante :
scalene preprocess.py
- Et pour avoir une sortie au format html (le format txt est actif par défaut) dans un fichier, utilisez la commande suivante :
scalene --html --outfile profile.html preprocess.py
Ce qui donne ce type de sortie :
Tableau de sortie de Scalene
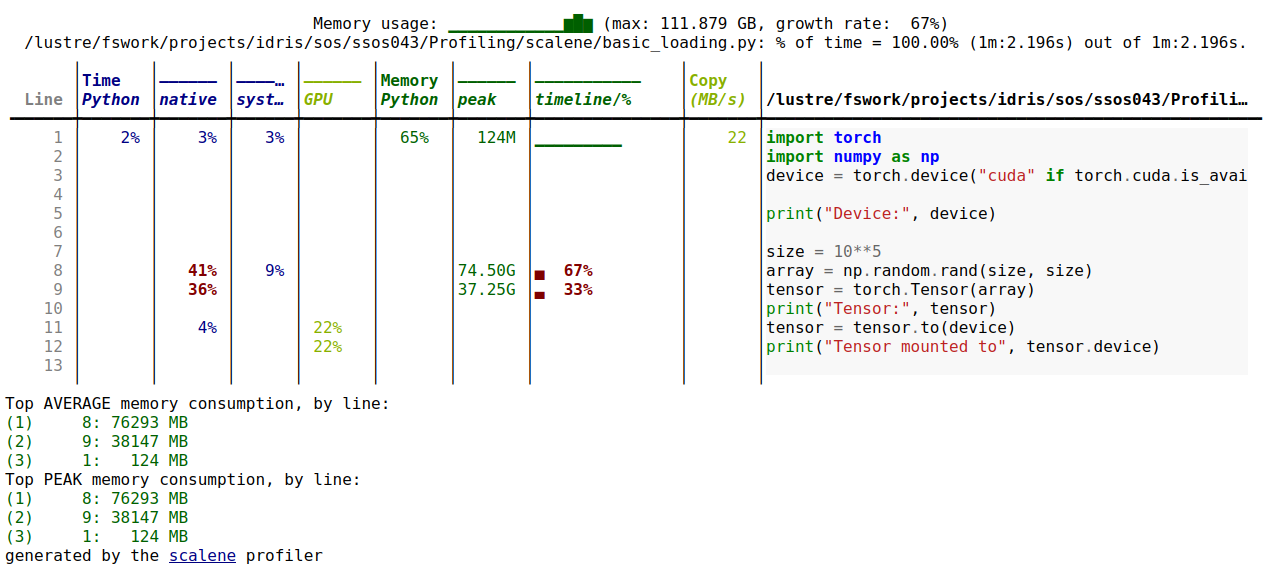
Pour ne profiler que certaines fonctions du code, il faut y ajouter le décorateur @profile (pas d'import nécessaire) :
@profile
def preprocess_data(dataframe, verbose=False):
...
Nous avons observé que Scalene pouvait causer de fréquentes Out Of Memory errors avec les codes PyTorch, pour l'instant inexpliquées.
Memory profiler
Ce profiler propose deux modes de fonctionnement, selon que l'on souhaite avoir un graphe temporel de l'évolution de la mémoire et/ou une sortie au format texte de cette évolution.
Le mode de base produit un fichier texte contenant les évolutions de la mémoire allouée et nécessite d'ajouter les instructions suivantes dans les codes à profiler :
# Import necessaire
from memory_profiler import profile
# Fichier de sortie du profiler
fp=open('memory_profiler.log','w+')
# Profiling de la fonction avec sortie dans le fichier choisi
@profile(stream=fp)
def create_tensor():
...
Notez que le décorateur @profile(stream=fp) peut servir autant de fois qu'on le souhaite pour autant de fonctions différentes.
L'exécution du code se fait alors sans changement via la commande python.
Le fichier memory_profiler.log contiendra alors ce type d'information :
Line # Mem usage Increment Occurrences Line Contents
=============================================================
7 356.1 MiB 356.1 MiB 1 @profile(stream=fp)
8 def create_tensor():
9 356.1 MiB 0.0 MiB 1 size = 10**5
10 76652.2 MiB 76296.1 MiB 1 array = np.random.rand(size,size)
11 114804.5 MiB 38152.3 MiB 1 _tensor = torch.Tensor(array) # Créé un objet Tensor
12
13 114809.9 MiB 5.4 MiB 1 device = torch.device("cuda" if torch.cuda.is_available() else "CPU")
14 114809.9 MiB 0.0 MiB 1 print("Device:", device)
15 76799.9 MiB -38010.1 MiB 1 _tensor = _tensor.to(device) # Le Tensor est déplacé vers la mémoire GPU
16 76799.9 MiB 0.0 MiB 1 print("Tensor mounted to", device)
17
18 505.9 MiB -76294.0 MiB 1 del array # Suppression de l'objet "array" de la mémoire
Il est possible de profiler la totalité du code en le lançant avec l'option -m memory profiler comme suit :
python -m memory_profiler example.py
Le second mode de fonctionnement permet d'obtenir un graphe des évolutions de la mémoire. Le code doit alors être exécuté via la commande mprof :
mprof run example.py
L'exécution génère alors un fichier dont le nom est du type mprofile_*.dat que l'on peut interpréter pour en extraire un graphique via la commande matplotlib.
Pour avoir le graphe du dernier profilage réalisé, il suffit de faire :
mprof plot
Si vous souhaitez visualiser un autre fichier, il vous suffit d'ajouter son nom dans la ligne de commande.
Exemple de graph Memory Profiler

Il est possible d'afficher sur le graphe quand commence et finit une fonction en utilisant le décorateur @profile (et en omettant l'instruction from memory_profiler import profile).
A noter que la génération du graphe nécessite l'accès à un environnement graphique (sur Jean Zay, utilisez les nœuds de visualisation), le plus simple étant d'utiliser cette fonctionnalité sur son ordinateur local.
L'outil Memory Profiler a de nombreux modes, qu'il est possible de voir en lançant mprof sans argument, puis mprof <mode> -h pour les options relatives à un mode donné.
Fil profiler
Ce profiler est la version open source d'un outil commercial. Il est assez limité mais en contrepartie son impact sur la durée d'exécution du programme est moindre.
Pour obtenir un flame graph (et donc l'endroit où se situe la portion de code la plus gourmande en mémoire), il faut lancer le code ainsi :
fil-profile run example.py
Cela génère un répertoire contenant un fichier html et 2 images vectorielles (svg) contenant chacune un flame graph :
Flame graph fil-profiler

Pour profiler une partie du code, il suffit de modifier le code ainsi :
from filprofiler.api import profile
_tensor = profile(lambda: create_tensor(), "fil-result")
et d'exécuter ensuite le code de cette manière (attention à bien utiliser fil-profiler python et non pas fil-profile run) :
fil-profile python example.py
Contrairement au décorateur utilisé par les autres profilers, cette manière de procéder permet de profiler une fonction en respectant des conditions (à implémenter soi-même dans le code via un if … else …), par exemple ne profiler que sur le rang master en cas de code multi-tâches.
py-spy
Le package py-spy contient trois utilitaires différents: record, top et dump permettant respectivement de générer un flame graph, de visualiser en temps réel l'activité au sein du processus Python et d'afficher le call stack actuel pour chaque thread Python.
Pour utiliser py-spy il est nécessaire de d'abord lancer votre code python en parallèle via un job slurm et ensuite de se connecter au nœud de calcul du job par ssh.
Une fois le job lancé, la commande squeue --me permet de récupérer le nœud de calcul assigné, et ssh <nœud> vous permet d'y accéder (ici nœud=jzxh017) :
sbatch training.pysubmitted batch job 24010squeue --me JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 241010 GPU_p6 training my_name R 0:04 1 jzxh017ssh jzxh017# Le shell est à présent sur le noeud jzxh017Il faut ensuite utiliser la commande top pour lister les processus tournant sur le nœud, et identifier le processus Python à profiler et son Process ID (PID) :
top PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 181501 use01jz 20 0 46,5g 147840 0 S 97,4 0,1 1:16.79 wandb 172547 use02jz 20 0 244216 5120 4480 R 69,7 0,0 3:07.09 rsync1769193 my_name 20 0 298028 31204 4480 R 63,2 0,0 0:18.65 python 181192 use05jz 20 0 72,5g 512764 17280 S 59,0 0,3 0:37.22 gitRapport de performance
Pour créer un flame graph, il suffit d'utiliser la sous commande record de py-spy en indiquant le processus voulu via --pid <PID> :
# Pour créer un flamegraph
py-spy record -o profile.svg --pid 1769193
SVG de sortie de py-spy record

Performance instantanée
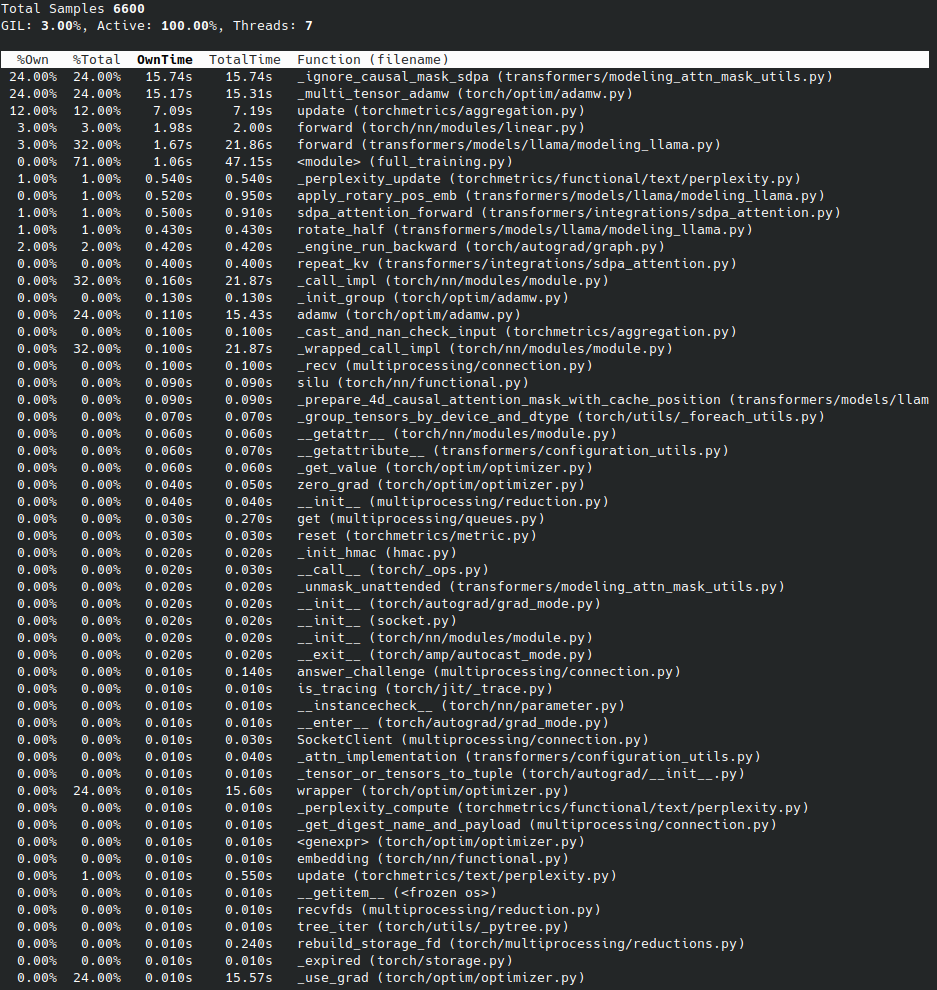
La sous commande top de py-spy est similaire à la commande top d'Unix et affiche en temps réel les fonctions qui consomment le plus de temps dans le programme pour le processus sélectionné via --pid <PID> :
py-spy top --pid 1769193
Cette commande met à jour l'affichage en continu, vous aidant ainsi à identifier rapidement les goulots d'étranglement au niveau des performances (bottleneck).
Sortie de py-spy top
Call stack
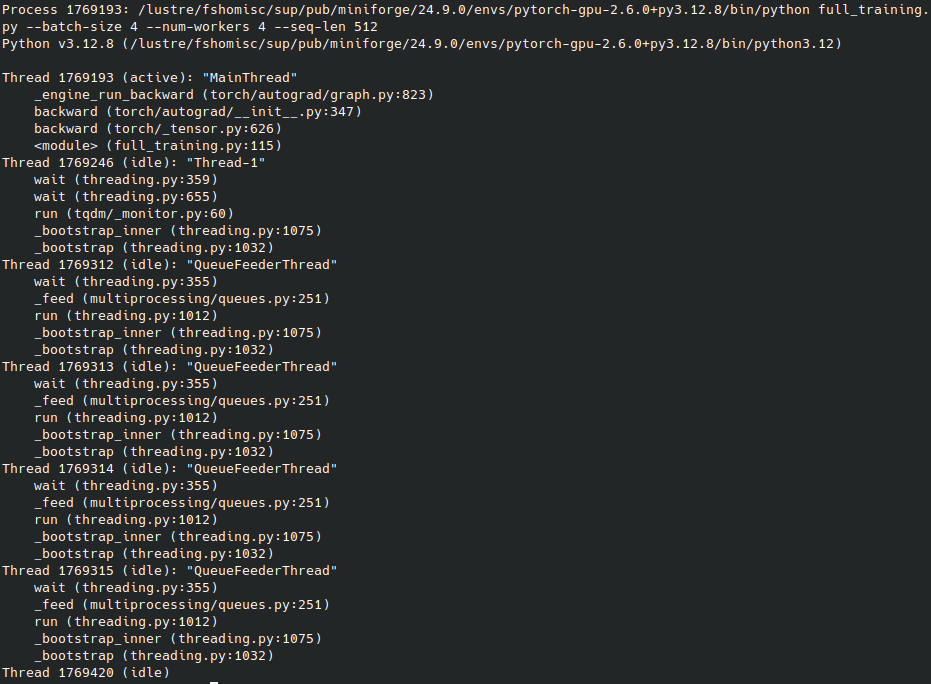
Pour avoir la call stack en temps réel, il suffit d'utiliser la sous commande dump de py-spy en indiquant le processus voulu via --pid <PID> :
# Pour obtenir le callstack instantané des threads
py-spy dump --pid 1769193 > full_training.dump
Ceci peut être utile pour détecter des blocages ou autres problèmes d'exécution.
Sortie de py-spy dump
Nsight Systems (NVIDIA)
Nsight-systems est disponible sur Jean Zay via les modules-files nvidia-nsight-systems (voir la sortie de la commande module avail nvidia-nsight-systems). Son utilisation requière de charger la version voulue via la commande module load nvidia-nsight-systems/.... Ensuite, il suffit d'utiliser la commande nsys profile comme suit:
srun nsys profile python example.py
Ceci générera un fichier reportX.nsys-rep qui sera interprétable par les autres commandes nsys.
Lors de l'exécution de plusieurs processus à profiler, il est possible de lancer une session avec nsys start puis de la terminer avec nsys stop, en profilant chaque processus souhaité avec nsys launch.
Voici un exemple de job slurm :
#!/bin/bash
#SBATCH --job-name=nsys_example
#SBATCH --output=%x_%j.out
#SBATCH --error=%x_%j.out#err
#SBATCH --gres=gpu:1
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --hint=nomultithread
#SBATCH --time=00:05:00
#SBATCH --cpus-per-task=24
#SBATCH -C h100
## load module
module purge
module load arch/h100
module load pytorch-gpu/py3/2.6.0
module load nvidia-nsight-systems/2024.7.1.84
## echo of launched commandes
set -x
nsys start
srun nsys launch python example.py # code profilé
srun python post.py # code intermédiaire non-profilé
srun nsys launch python example2.py # code profilé
nsys stop
Investigation manuelle et ponctuelle
C'est la méthode la moins intrusive pour explorer des parties de code, en particulier si vous soupçonnez où se situe un problème potentiel.
Ces codes pourront être rassemblés dans un fichier tools.py (à rendre accessible via $PYTHONPATH par exemple).
Information sur la durée d'exécution d'une fonction
Il suffit de définir les fonctions suivantes :
import time
from functools import wraps
def convert_time(seconds):
return time.strftime("%H:%M:%S", time.gmtime(seconds))
def timing(func):
@wraps(func)
def wrap(*args, **kw):
start_time = time.time()
result = func(*args, **kw)
duration = time.time() - start_time
print(f"________ Duration of {func.__name__}(): {convert_time(duration)} \t {duration} seconds")
return result
return wrap
On utilise alors cette fonction timing via un décorateur :
from tools import timing
@timing
def suspicious_function():
...
La manière d'exécuter le code est inchangée.
Une information similaire à celle ci-dessous apparaîtra dans la sortie du programme (ou dans le fichier défini via la directive Slurm --output si lancement via sbatch).
________ Duration of suspicious_function(): 00:00:18 18.34224474 seconds
Information sur la mémoire réservée
Cette méthode n'est pas forcément fiable, et peut sous estimer la réelle occupation mémoire (ce qui est aussi le cas des outils présentés plus haut). Cela peut aussi ne pas être adéquat selon la complexité de la structure de données que vous souhaitez évaluer (voir les handlers dans le code ci-joint).
Dans le même ordre d'idée que la fonction timing ci-dessus, on va définir dans un fichier tools.py, les fonctions suivantes :
from sys import getsizeof, stderr
from itertools import chain
from collections import deque
try:
from reprlib import repr
except ImportError:
pass
def convert_byte(num, suffix="B"):
for unit in ["", "Ki", "Mi", "Gi", "Ti", "Pi", "Ei", "Zi"]:
if abs(num) < 1024.0:
return f"{num:3.1f}{unit}{suffix}"
num /= 1024.0
return f"{num:.1f}Yi{suffix}"
def total_size(object_name, o, handlers={}, verbose=False):
""" Returns the approximate memory footprint an object and all of its contents.
Automatically finds the contents of the following builtin containers and
their subclasses: tuple, list, deque, dict, set and frozenset.
To search other containers, add handlers to iterate over their contents:
handlers = {SomeContainerClass: iter,
OtherContainerClass: OtherContainerClass.get_elements}
"""
dict_handler = lambda d: chain.from_iterable(d.items())
all_handlers = {tuple: iter,
list: iter,
deque: iter,
dict: dict_handler,
set: iter,
frozenset: iter,
}
all_handlers.update(handlers) # user handlers take precedence
seen = set() # track which object id's have already been seen
default_size = getsizeof(0) # estimate sizeof object without __sizeof__
def sizeof(o):
if id(o) in seen: # do not double count the same object
return 0
seen.add(id(o))
s = getsizeof(o, default_size)
if verbose:
print(f"________ Memory consumption of {object_name} ({type(o)}) {convert_byte(s)}")
for typ, handler in all_handlers.items():
if isinstance(o, typ):
s += sum(map(sizeof, handler(o)))
break
return s
return sizeof(o)