Outils IDRIS pour Slurm
slurmtop
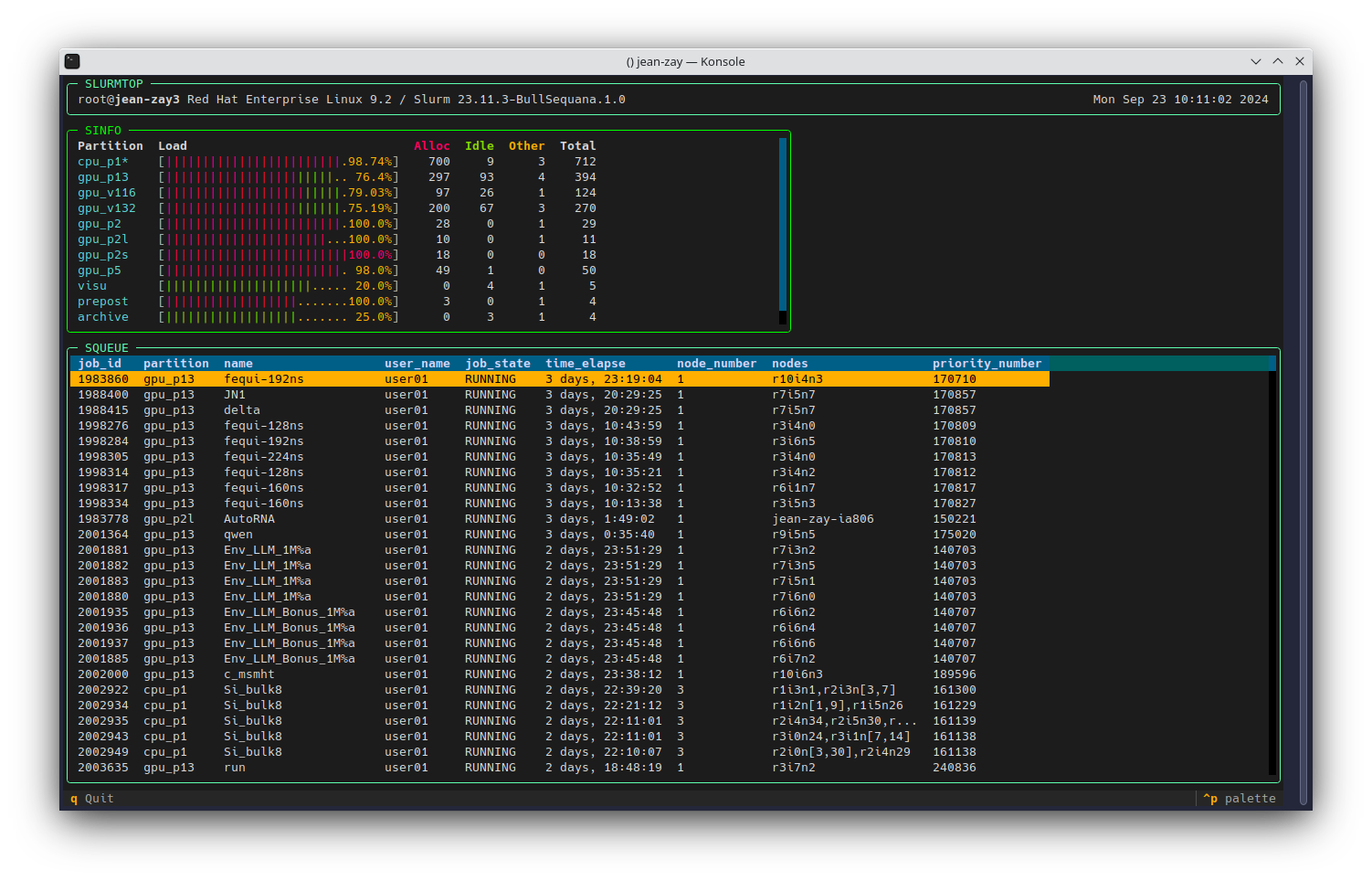
Slurmtop permet de visualiser rapidement et graphiquement (depuis le terminal) les états de charge des différentes partitions d'un cluster Slurm.
Slurmtop est disponible via la commande slurmtop depuis le module python
par défaut module load python.
idr_pytools
Nous mettons à disposition des utilisateurs de Jean Zay des scripts pour l'exécution automatisée de travaux GPU via le gestionnaire de travaux Slurm. Ces scripts ont été créés pour être exploités dans un notebook ouvert sur une frontale afin d'exécuter des travaux distribués sur les nœuds de calcul GPU.
Les scripts sont développés par l'assistance IDRIS et installés dans tous les modules PyTorch ou TensorFlow.
Import des fonctions :
from idr_pytools import gpu_jobs_submitter, display_slurm_queue, search_log
Soumission de travaux GPU
Le script gpu_jobs_submitter permet de soumettre des travaux GPU dans
la queue Slurm. Il automatise la création de fichiers Slurm conformes à
nos prescriptions et soumet via la commande sbatch les travaux pour
exécution.
Les fichiers Slurm automatiquement créés se trouvent dans le dossier slurm. Vous pouvez les consulter afin de valider la configuration.
Arguments
- srun_commands (obligatoire) : la commande à exécuter avec
srun. Pour l'IA, il s'agit souvent d'un script python à exécuter. Exemple :'my_script.py -b 64 -e 6 --learning-rate 0.001'. Si le premier mot est un fichier d'extension .py, la commandepython -uest rajouté automatiquement avant le nom du script. Il est possible aussi d'indiquer une liste de commandes pour soumettre plusieurs travaux. Exemple :['my_script.py -b 64 -e 6 --learning-rate 0.001', 'my_script.py -b 128 -e 12 --learning-rate 0.01']. - n_gpu : le nombre de GPU à réserver pour un travail. Par défaut
1 GPU et au maximum 512 GPU. Il est possible aussi d'indiquer une
liste de nombres de GPU. Exemple :
n_gpu=[1, 2, 4, 8, 16]. Ainsi un travail sera créé pour chaque élément de la liste. Si plusieurs commandes sont spécifiées dans l'argument précédentsrun_commands, chaque commande sera lancée sur l'ensemble des configurations demandées. - module (obligatoire si on utilise les modules) : nom du module à charger, un seul nom de module autorisé.
- singularity (obligatoire si on utilise un conteneur Singularity)
: nom de l'image SIF à charger. La commande
idrcontmgraura préalablement été appliquée, voir la documentation sur l'utilisation des conteneurs Singularity. - name : nom du travail. Il sera affiché dans la queue Slurm et
intégré aux noms des logs. Par défaut, le nom du script python
indiqué dans
srun_commandsest utilisé. - n_gpu_per_task : le nombre de GPU associés à une tâche. Par défaut, 1 GPU pour une tâche conformément à la configuration du parallélisme de données. Cependant, pour le parallélisme de modèle ou pour les stratégies de distribution Tensorflow, il sera nécessaire d'associer plusieurs GPU à une tâche.
- time_max : la durée maximale du travail. Par défaut :
'02:00:00'. - qos : la QoS à utiliser si différente de la QoS
(
'qos_gpu-t3') par défaut. - partition : la partition à utiliser si différente de la
partition (
'gpu_p13') par défaut. - constraint :
'v100-32g' ou'v100-16g'. Lorsque l'on utilise la partition par défaut, cela permet de forcer l'utilisation des GPU 32Go ou des GPU 16Go. - cpus_per_task : le nombre de CPU à associer à chaque tâche,
par défaut : 10 pour la partition par défaut, 3 pour la partition
gpu_p2, 8 pour la partitiongpu_p5et 24 pour la partitiongpu_p6. Il est conseillé de laisser les valeurs par défaut. - exclusive : force l'utilisation d'un nœud en exclusivité.
- account : attribution d'heures GPU à utiliser. Obligatoire si vous avez accès à plusieurs attributions d'heures et/ou de projets. Pour plus d'information, vous pouvez vous référer à notre documentation à propos de la gestion des heures de calcul par projet.
- verbose : par défaut
0. La valeur1rajoute les traces de débogage NVIDIA dans les logs. - email : adresse email pour l'envoi automatique de rapports d'état de vos travaux par Slurm.
- addon : permet d'ajouter des lignes de commandes additionnelles
dans le fichier Slurm, par exemple
'unset PROXY', ou par exemple pour charger un environnement personnel :addon="""source .bashrcconda activate myEnv"""
Pour utiliser la partition A100 ou H100, il faudra juste le préciser avec
account=xxx@a100 ou account=xxx@h100 ("xxx" désigne le groupe unix ; voir la sortie de la commande idrproj). Ensuite, l'ajout de la contrainte
et du module nécessaire pour utiliser cette partition seront automatiquement
intégrés au fichier .slurm généré.
Retour
- jobids : liste des jobids des travaux soumis.
Exemple
- Commande lancée :
jobids = gpu_jobs_submitter(['my_script.py -b 64 -e 6 --learning-rate 0.001',
'my_script.py -b 128 -e 12 --learning-rate 0.01'],
n_gpu=[1, 2, 4, 8, 16, 32, 64],
module='tensorflow-gpu/py3/2.4.1',
name="Imagenet_resnet101")
- Affichage :
batch job 0: 1 GPUs distributed on 1 nodes with 1 tasks / 1 gpus per node and 3 cpus per task
Submitted batch job 778296
Submitted batch job 778297
batch job 2: 2 GPUs distributed on 1 nodes with 2 tasks / 2 gpus per node and 3 cpus per task
Submitted batch job 778299
Submitted batch job 778300
batch job 4: 4 GPUs distributed on 1 nodes with 4 tasks / 4 gpus per node and 3 cpus per task
Submitted batch job 778301
Submitted batch job 778302
batch job 6: 8 GPUs distributed on 1 nodes with 8 tasks / 8 gpus per node and 3 cpus per task
Submitted batch job 778304
Submitted batch job 778305
batch job 8: 16 GPUs distributed on 2 nodes with 8 tasks / 8 gpus per node and 3 cpus per task
Submitted batch job 778306
Submitted batch job 778307
batch job 10: 32 GPUs distributed on 4 nodes with 8 tasks / 8 gpus per node and 3 cpus per task
Submitted batch job 778308
Submitted batch job 778309
batch job 12: 64 GPUs distributed on 8 nodes with 8 tasks / 8 gpus per node and 3 cpus per task
Submitted batch job 778310
Submitted batch job 778312
Affichage interactif de la queue Slurm
Sur un notebook, il est possible d'afficher la queue Slurm et les
travaux en attente avec la commande suivante : squeue -u $USER
Cependant, cela affiche seulement l'état présent.
La fonction display_slurm_queue permet d'avoir un affichage dynamique de la queue, rafraîchi toutes les 5 secondes. La fonction s'arrête seulement lorsque la queue est vide, ce qui est pratique dans un notebook pour avoir une exécution séquentielle des cellules. Si les travaux durent trop longtemps, il est possible de stopper l'exécution de la cellule (sans impact sur la queue Slurm) pour reprendre la main sur le notebook.
Arguments
- name : permet un filtrage par nom de job. La queue n'affiche que les travaux avec ce nom.
- timestep : temps de rafraîchissement, par défaut : 5 secondes.
Exemple
- Commande lancée :
display_slurm_queue("Imagenet_resnet101")
- Affichage :
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
778312 gpu_p2 Imagenet ssos040 PD 0:00 8 (Priority)
778310 gpu_p2 Imagenet ssos040 PD 0:00 8 (Priority)
778309 gpu_p2 Imagenet ssos040 PD 0:00 4 (Priority)
778308 gpu_p2 Imagenet ssos040 PD 0:00 4 (Priority)
778307 gpu_p2 Imagenet ssos040 PD 0:00 2 (Priority)
778306 gpu_p2 Imagenet ssos040 PD 0:00 2 (Priority)
778305 gpu_p2 Imagenet ssos040 PD 0:00 1 (Priority)
778304 gpu_p2 Imagenet ssos040 PD 0:00 1 (Priority)
778302 gpu_p2 Imagenet ssos040 PD 0:00 1 (Priority)
778301 gpu_p2 Imagenet ssos040 PD 0:00 1 (Priority)
778296 gpu_p2 Imagenet ssos040 PD 0:00 1 (Resources)
778297 gpu_p2 Imagenet ssos040 PD 0:00 1 (Resources)
778300 gpu_p2 Imagenet ssos040 PD 0:00 1 (Resources)
778299 gpu_p2 Imagenet ssos040 R 1:04 1 jean-zay-ia828
Recherche de chemins de logs
La fonction search_log permet de retrouver les chemins vers les fichiers de logs des travaux exécutés avec la fonction gpu_jobs_submitter.
Les fichiers de log ont un nom avec le format suivant :
'{name}@JZ_{datetime}_{ntasks}tasks_{nnodes}nodes_{jobid}'.
Arguments
- name : permet un filtrage par nom de travaux.
- contains : permet un filtrage par date, nombre de tâches, nombre
de nœuds ou jobid. Le caractère '*' permet de concaténer
plusieurs filtres. Exemple :
contains='2021-02-12_22:*1node' - with_err : par défaut False. Si True, retourne un dictionnaire avec les chemins des fichiers de sortie et des fichiers d'erreur listés par ordre chronologique. Si False, retourne une liste avec seulement les chemins des fichiers de sortie listés par ordre chronologique.
Exemple
- Commande lancée :
paths = search_log("Imagenet_resnet101")
- Affichage :
`['./slurm/log/Imagenet_resnet101@JZ_2021-04-01_11:23:46_8tasks_4nodes_778096.out',
'./slurm/log/Imagenet_resnet101@JZ_2021-04-01_11:23:49_8tasks_4nodes_778097.out',
'./slurm/log/Imagenet_resnet101@JZ_2021-04-01_11:23:53_8tasks_4nodes_778099.out',
'./slurm/log/Imagenet_resnet101@JZ_2021-04-01_11:23:57_8tasks_8nodes_778102.out',
'./slurm/log/Imagenet_resnet101@JZ_2021-04-01_11:24:04_8tasks_8nodes_778105.out',
'./slurm/log/Imagenet_resnet101@JZ_2021-04-01_11:24:10_8tasks_8nodes_778110.out',
'./slurm/log/Imagenet_resnet101@JZ_2021-04-07_17:53:49_2tasks_1nodes_778310.out',
'./slurm/log/Imagenet_resnet101@JZ_2021-04-07_17:53:52_2tasks_1nodes_778312.out']
Les chemins sont classés par ordre chronologique. Si vous voulez les 2 derniers chemins, il suffit d'utiliser la commande suivante :
paths[-2:]