Parallélisme de données
Le parallélisme de données (Data Parallelism) permet d'accélérer l'apprentissage du modèle en utilisant plusieurs GPU. Il est adapté aux apprentissages impliquant des données volumineuses ou des batches de grande taille.
Il s'agit du procédé de distribution le plus documenté et le plus facile à mettre en œuvre.
Le parallélisme de données peut être combiné avec le parallélisme de modèle dans le cas où le modèle à entraîner est trop volumineux pour tenir en mémoire sur un seul GPU. Voir la page de documentation dédiée au parallélisme hybride.
Principe
Le parallélisme de données consiste à répliquer le modèle sur l'ensemble des GPU et à diviser le batch de données en mini-batches. Chaque GPU prend alors en charge un mini-batch pour un apprentissage en parallèle sur l'ensemble des mini-batches.

Schéma de distribution d'un batch de données sur 256 GPU. Source.
Dans ce cas, le processus d'entraînement est le suivant :
- Le script d'apprentissage est exécuté en mode distribué sur plusieurs processus (i.e. plusieurs GPU). Ainsi, chaque GPU :
- lit une partie des données (mini-batch) ;
- entraîne le modèle à partir de son mini-batch ;
- calcule les gradients à partir des informations qu'il a localement (gradients locaux).
- Les gradients globaux sont calculés en moyennant les gradients locaux retournés par l'ensemble des GPU. Il est nécessaire à cette étape de synchroniser les différents processus.
- Le modèle est mis à jour sur chacun des GPU.
- L'algorithme est répété jusqu'à la fin de l'apprentissage.
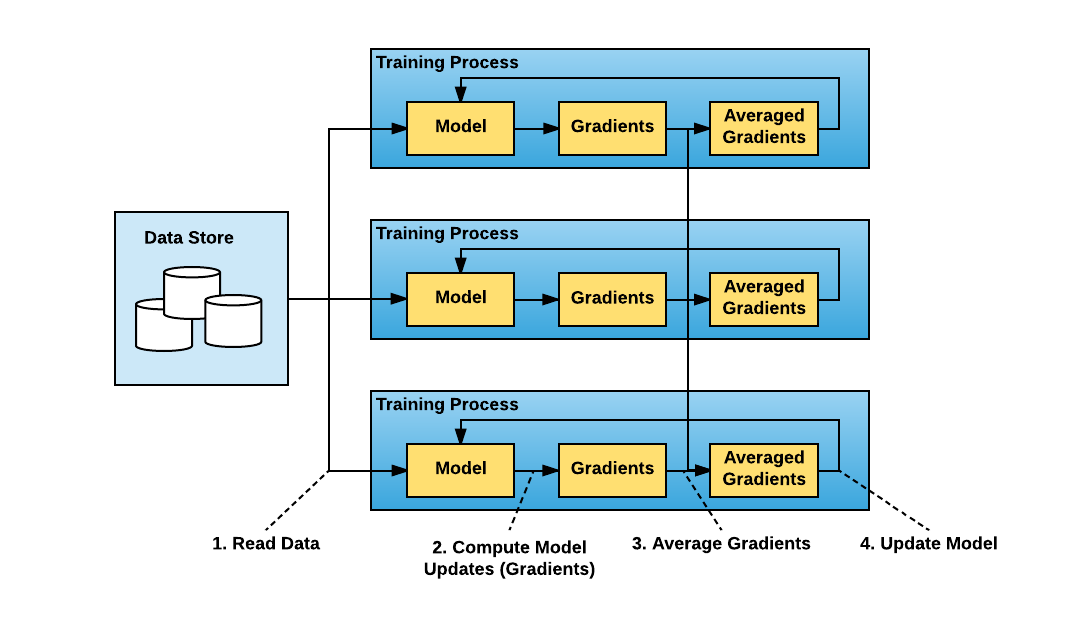
Représentation d'un apprentissage distribué sur 3 GPU selon la méthode de parallélisme de données. Source.
Mise en pratique
- Mise en pratique avec PyTorch
- Mise en pratique avec Pytorch Lightning
- Mise en pratique avec TensorFlow
- Mise en pratique avec Horovod
Ressources
- La formation Deep learning Optimisé sur Jean-Zay proposée par l'IDRIS couvre, parmi d'autres thématiques, la parallélisation de l’entraînement, y compris le parallélisme de données. Plus d’informations sont disponibles ici.