Parallélisme de données avec PyTorch Lightning
Cette page explique comment distribuer un modèle neuronal artificiel implémenté dans un code Pytorch Lightning, selon la méthode du parallélisme de données.
Un exemple applicatif est proposé sous forme d'un Notebook en bas de page pour vous permettre d'accéder à une implémentation fonctionnelle des explications données ci-dessous.
Avant d'aller plus loin, il est obligatoire d'avoir les bases concernant l'utilisation de Pytorch Lightning. La documentation de Pytorch Lightning est très complète et propose beaucoup d'exemples.
Configuration multi-process avec Slurm
Pour le multi-nœuds, il est nécessaire d'utiliser le multi-processing géré par Slurm (exécution via la commande Slurm srun). Pour le
mono-nœud il est possible d'utiliser, comme la documentation PyTorch l'indique, torch.multiprocessing.spawn. Cependant il est possible et plus pratique d'utiliser le multi-processing Slurm dans tous les cas, en mono-nœud ou en multi-nœuds. C'est ce que nous documentons dans cette page.
Dans Slurm, lorsqu'on lance un script avec la commande srun, le script est automatiquement distribué sur toutes les tâches prédéfinies. Par exemple, si nous réservons 4 nœuds en demandant 3 GPU par nœud, nous obtenons :
- 4 nœuds, indexés de 0 à 3
- 3 GPU/nœud indexés de 0 à 2 sur chaque nœud
- 4 x 3 = 12 processus au total permettant d'exécuter 12 tâches avec les rangs indexés de 0 à 11
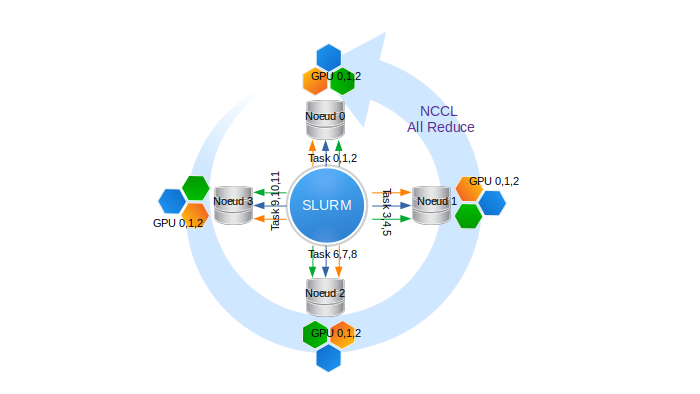
Illustration d'une réservation Slurm de 4 nœuds et 3 GPU par nœud, soit 12 processus.
Les communications collectives inter-nœuds sont gérées par la librairie NCCL.
Voici deux exemples de script Slurm pour Jean-Zay :
- pour une réservation de N nœuds quadri-GPU V100 via la partition GPU par défaut :
#!/bin/bash
#SBATCH --job-name=torch-multi-gpu
#SBATCH --nodes=N # nombre total de noeuds (N à définir)
#SBATCH --ntasks-per-node=4 # nombre de taches par noeud (ici 4 taches soit 1 tache par GPU)
#SBATCH --gres=gpu:4 # nombre de GPU reserve par noeud (ici 4 soit tous les GPU)
#SBATCH --cpus-per-task=10 # nombre de coeurs par tache (donc 4x10 = 40 coeurs soit tous les coeurs)
#SBATCH --hint=nomultithread
#SBATCH --time=20:00:00
#SBATCH --output=torch-multi-gpu%j.out
##SBATCH --account=abc@v100
module load pytorch-gpu/py3/2.5.0
srun python myscript.py
- pour une réservation de N nœuds octo-GPU A100 :
#!/bin/bash
#SBATCH --job-name=torch-multi-gpu
#SBATCH --nodes=N # nombre total de noeuds (N à définir)
#SBATCH --ntasks-per-node=8 # nombre de taches par noeud (ici 8 taches soit 1 tache par GPU)
#SBATCH --gres=gpu:8 # nombre de GPU reserve par noeud (ici 8 soit tous les GPU)
#SBATCH --cpus-per-task=8 # nombre de coeurs par tache (donc 8x8 = 64 coeurs soit tous les coeurs)
#SBATCH --hint=nomultithread
#SBATCH --time=20:00:00
#SBATCH --output=torch-multi-gpu%j.out
#SBATCH -C a100
##SBATCH --account=abc@a100
module load arch/a100
module load pytorch-gpu/py3/2.5.0
srun python myscript.py
Dans ces deux exemples, les nœuds sont réservés en exclusivité. En particulier, cela nous donne accès à toute la mémoire de chaque nœud.
Configuration et stratégie de distribution de Pytorch Lightning
La documentation entraînement multi-GPU permet de découvrir la majorité des configurations et stratégies possibles (dp, ddp, ddp_spawn, ddp2, horovod, deepspeed, fairscale, etc).
Sur Jean Zay, on recommande d'utiliser la stratégie ddp car c'est celle qui a le moins de restriction sur Pytorch Lightning. C'est la
même chose que le DistributedDataParallel fourni par PyTorch mais à travers la surcouche Lightning.
Lightning sélectionne par défaut le backend NCCL. C'est ce qui est le plus performant sur Jean Zay mais on peut aussi utiliser GLOO et MPI.
L'utilisation de cette stratégie se gère dans les arguments du Trainer. Voici un exemple d'implémentation possible qui récupère directement les variables d'environnement Slurm :
trainer_args = {'accelerator': 'gpu',
'devices': int(os.environ['SLURM_GPUS_ON_NODE']),
'num_nodes': int(os.environ['SLURM_NNODES']),
'strategy': 'ddp'}
trainer = pl.Trainer(**trainer_args)
trainer.fit(model)
Les quelques essais de performance réalisés sur Jean Zay, montrent que la surcouche Lightning génère, dans le meilleur des cas, une perte de performance temporelle de l'ordre de 5% par rapport à DistributedDataParallel de PyTorch. On retrouve cet ordre de grandeur sur les tests de référence réalisés par Lightning. Lightning se veut être une interface de haut-niveau, il est donc normal d'échanger de la performance contre une facilité d'implémentation.
Sauvegarde et chargement de checkpoints
Lorsque vous utilisez une version récente de Lightning, il est nécessaire d'ajouter
export TMPDIR=$JOBSCRATCH
au début de votre script de soumission pour éviter une erreur de quota sur le répertoire temporaire par défaut /tmp qui est très petit sur les nœuds de calcul de Jean Zay.
Sauvegarde
Par défaut Lightning, réalise automatiquement la sauvegarde de checkpoints.
En multi-GPU, Lightning s'assure que la sauvegarde n'est réalisée que par le processus principal. Il n'y a pas de code spécifique à ajouter.
trainer = Trainer(strategy="ddp")
model = MyLightningModule(hparams)
trainer.fit(model)
# Saves only on the main process
trainer.save_checkpoint("example.ckpt")
Afin d'éviter des conflits de sauvegarde, Lightning préconise de toujours utiliser la fonction save_checkpoint(). Si vous utilisez une fonction "maison", il faut penser à décorer celle-ci avec rank_zero_only().
from pytorch_lightning.utilities import rank_zero_only
@rank_zero_only
def homemade_save_checkpoint(path):
...
homemade_save_checkpoint("example.ckpt")
Chargement
Au début d'un apprentissage, le chargement d'un checkpoint est d'abord opéré par le CPU, puis l'information est envoyée sur le GPU. Là encore pas de code spécifique à ajouter, Lightning s'occupe de tout.
#On importe les poids du modèle pour un nouvel apprentissage
model = LitModel.load_from_checkpoint(PATH)
#Ou on restaure l'entraînement précédent (model, epoch, step, LR schedulers, apex, etc...)
model = LitModel()
trainer = Trainer()
trainer.fit(model, ckpt_path="some/path/to/my_checkpoint.ckpt")
Validation distribuée
L'étape de validation exécutée après chaque epoch ou après un nombre fixé d'itérations d'apprentissage peut se distribuer sur tous les GPU engagés dans l'apprentissage du modèle. La validation est, par défaut, distribuée sur Lightning dès que l'on passe en multi-GPU. Lorsque le parallélisme de données est utilisé et que l'ensemble des données de validation est conséquent, cette solution de validation distribuée sur les GPU semble être la plus efficace et la plus rapide.
Ici, l'enjeu est de calculer les métriques (loss, accuracy, etc...) par batch et par GPU, puis de les pondérer et de les moyenner sur l'ensemble des données de validation.
Si vous utilisez des métriques natives ou basées sur torchmetric, il n'y a rien à faire.
class MyModel(LightningModule):
def __init__(self):
...
self.accuracy = torchmetrics.Accuracy()
def training_step(self, batch, batch_idx):
x, y = batch
preds = self(x)
...
# log step metric
self.accuracy(preds, y)
self.log("train_acc_step", self.accuracy, on_epoch=True)
...
Dans le cas inverse il faut réaliser une synchronisation lors du logging :
def validation_step(self, batch, batch_idx):
x, y = batch
logits = self(x)
loss = self.loss(logits, y)
# Add sync_dist=True to sync logging across all GPU workers (may have performance impact)
self.log("validation_loss", loss, on_step=True, on_epoch=True, sync_dist=True)
def test_step(self, batch, batch_idx):
x, y = batch
tensors = self(x)
return tensors
def test_epoch_end(self, outputs):
mean = torch.mean(self.all_gather(outputs))
# When logging only on rank 0, don't forget to add
# ``rank_zero_only=True`` to avoid deadlocks on synchronization.
if self.trainer.is_global_zero:
self.log("my_reduced_metric", mean, rank_zero_only=True)
Exemple d'application
Exécution multi-GPU, multi-nœuds avec "ddp" sur Pytorch Lightning
Un exemple se trouve dans $DSDIR/examples_IA/Torch_parallel/Example_DataParallelism_PyTorch_Lightning.ipynb sur Jean-Zay, il utilise la base de données CIFAR et un Resnet50. L'exemple est un Notebook qui permet de créer un script d'exécution. Il est à copier sur votre espace personnel (idéalement sur votre $WORK).
cp $DSDIR/examples_IA/Torch_parallel/Example_DataParallelism_PyTorch_Lightning.ipynb $WORK
Vous pouvez ensuite exécuter le Notebook à partir d'une machine frontale de Jean Zay en sélectionnant un noyau PyTorch (voir notre documentation sur l'accès à JupyterHub pour en savoir plus sur l'usage des Notebooks sur Jean Zay).