Parallélisme de modèle
Le parallélisme de modèle n'est pas évident à mettre en place et n'apporte aucun gain de performance (au contraire). Il est préférable de ne l'utiliser qu'en dernier recours.
Pour réduire l'empreinte mémoire de votre entraînement, vous pouvez dans un premier temps implémenter d'autres optimisations comme, par exemple, le Gradient Checkpointing ou ZeRO de Deepspeed.
Le parallélisme de modèle consiste à segmenter un modèle sur plusieurs GPUs afin de réduire l'empreinte mémoire du modèle sur chaque GPU (nécessaire pour des modèles trop gros ne pouvant pas tenir dans la mémoire d'un seul GPU). En théorie, l'occupation mémoire par GPU est ainsi divisée par le nombre de GPUs.
Le modèle est divisé en groupe de couches successives (nommées séquences) et chaque GPU prend en charge uniquement une de ces séquences, ce qui limite le nombre de paramètres à traiter localement.
Contrairement au parallélisme de données, il n'est pas nécessaire de synchroniser les gradients : les GPUs collaborent de manière séquentielle lors de chaque itération d'apprentissage.
Le parallélisme de modèle peut être combiné avec le parallélisme de données. Pour plus d'informations, consultez la page de documentation dédiée au parallélisme hybride.
La figure suivante illustre une parallélisation du modèle sur 2 GPUs, divisant ainsi par deux la taille mémoire occupée dans un GPU :
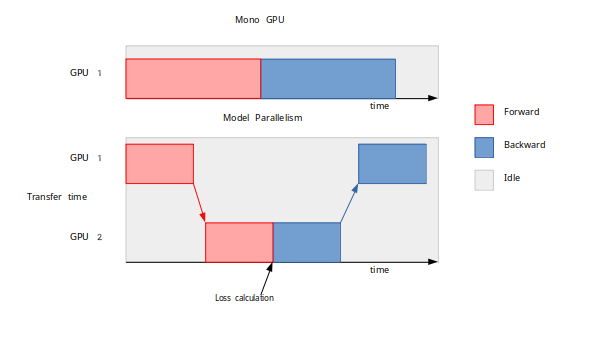
Illustration d'un entraînement distribué sur 2 GPUs selon la méthode de parallélisme de modèle
On note que le parallélisme de modèle n'accélère pas l'apprentissage car un GPU doit attendre que les couches antérieures du modèle aient été traitées par un autre GPU avant de pouvoir exécuter ses propres couches. L'apprentissage est même un peu plus long à cause des temps de transfert des données entre GPUs.
Néanmoins, il est possible et conseillé d'optimiser le procédé pour gagner du temps en utilisant une technique de data pipeline : la segmentation de batch (on parle alors de Pipeline Parallelism). Cela consiste à diviser le batch en sous-batches afin de limiter les temps d'attente et de faire travailler les GPUs quasi-simultanément. Cependant il y aura toujours un petit temps d'attente (la bulle sur le schéma ci-dessous).
Le schéma ci-dessous illustre la quasi-simultanéité et le gain obtenu grâce à la technique de segmentation lorsque le batch de données est divisé en 4 sous-batches, pour un entraînement distribué sur 4 GPUs :
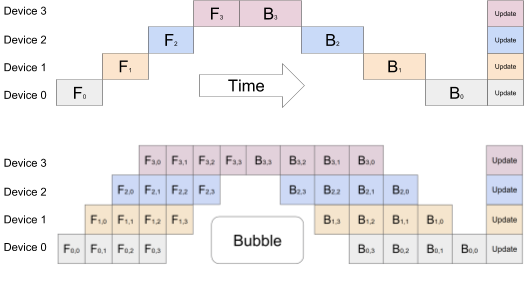
Comparaison entre parallèlisme de modèle basique et en pipeline avec 4 sous-batches. (Source:GPipe)
Le nombre optimal de sous-batches dépend du modèle considéré.
Pipeline Parallelism avec PyTorch
Pour les raisons évoquées ci-dessus, la version naïve du parallelisme de modèle n'est vraiment pas conseillée. Nous ne considérerons donc que la version optimisée du parallélisme de modèle : le Pipeline Parallelism.
La méthodologie présentée dans cette section montre comment adapter sur Jean Zay, un modèle trop volumineux pour tenir sur un seul GPU avec PyTorch.
La documentation PyTorch est très complète sur ce sujet ; il ne faudra faire que quelques légères modifications pour faire marcher le modèle parallélisme avec segmentation de batch (Pipeline Parallelism) sur Jean Zay. Si vous débutez avec le parallélisme de modèle, nous vous conseillons de suivre d'abord le tutoriel PyTorch à ce sujet.
Ce document présente uniquement les changements à faire pour paralléliser un modèle sur Jean Zay et présente un benchmark pour donner une idée de l'optimisation des paramètres de la méthode.
Exemple
Une démonstration complète (qui a servi au benchmark) se trouve dans un code python téléchargeable ici ou récupérable sur Jean-Zay dans le répertoire DSDIR : /examples_IA/Torch_parallel/bench_PP_transformer.py. Pour le copier dans votre espace $WORK :
cp $DSDIR/examples_IA/Torch_parallel/bench_PP_transformer.py $WORK
D'autres méthodes d'implémentation du parallélisme de modèle avec PyTorch existent et sont expliquées dans le lien suivant : Single-Machine Model Parallel Best Practices. Néanmoins, elles semblent moins efficaces que la méthode présentée dans cette page.
Configuration de l'environnement de calcul Slurm
Une seule tâche doit être déclarée pour un modèle (ou ensemble de modèles) ainsi que le nombre adéquat de GPU qui doivent tous être sur le même nœud. Si l'on prend l'exemple d'un modèle que l'on voudrait répartir sur 4 GPUs, les options suivantes sont exigées :
#SBATCH --gres=gpu:4
#SBATCH --ntasks-per-node=1
La méthodologie présentée ici, qui ne dépend que de la bibliothèque PyTorch, se limite à un parallélisme mono-nœud multi-GPU (de 2 GPUs à 4 GPUs ou 8 GPUs suivant le nœud utilisé) et ne peut pas s'appliquer à un cas multi-nœuds.
Il est vivement conseillé d'associer cette technique avec du parallélisme de données, comme décrit dans la page Parallélisme hybride (modèle et données), pour accélérer efficacement les entraînements.
Si votre modèle nécessite un parallélisme de modèle sur plusieurs nœuds, nous vous invitons à explorer les solutions documentées sur la page Distributed Pipeline Parallelism Using RPC ou à utiliser d'autres méthodes comme Deepspeed ou Megatron.
Benchmark
Un benchmark a été réalisé pour comparer le Pipeline Parallelism (avec différents paramètres) avec le parallélisme de modèle naïf. Les tests ont été réalisés sur 2 et 4 GPUs, donc avec un modèle coupé en deux ou en quatre parties (séquences). Le modèle utilisé est un Transformer qui est entraîné sur le dataset IMDB Review (le but est de mesurer les performances de l’entraînement bien qu'utiliser un Transformer pour une tâche si peu complexe est déconseillé). Différents batch sizes ont aussi été testés, de 32 à 256, combinés avec différents chunks, de 1 (parallélisme naïf) à 16. Les résultats sont les suivants (lorsqu'une donnée est manquante c'est qu'une occupation mémoire trop importante a eu lieu et le calcul est alors automatiquement terminé) :
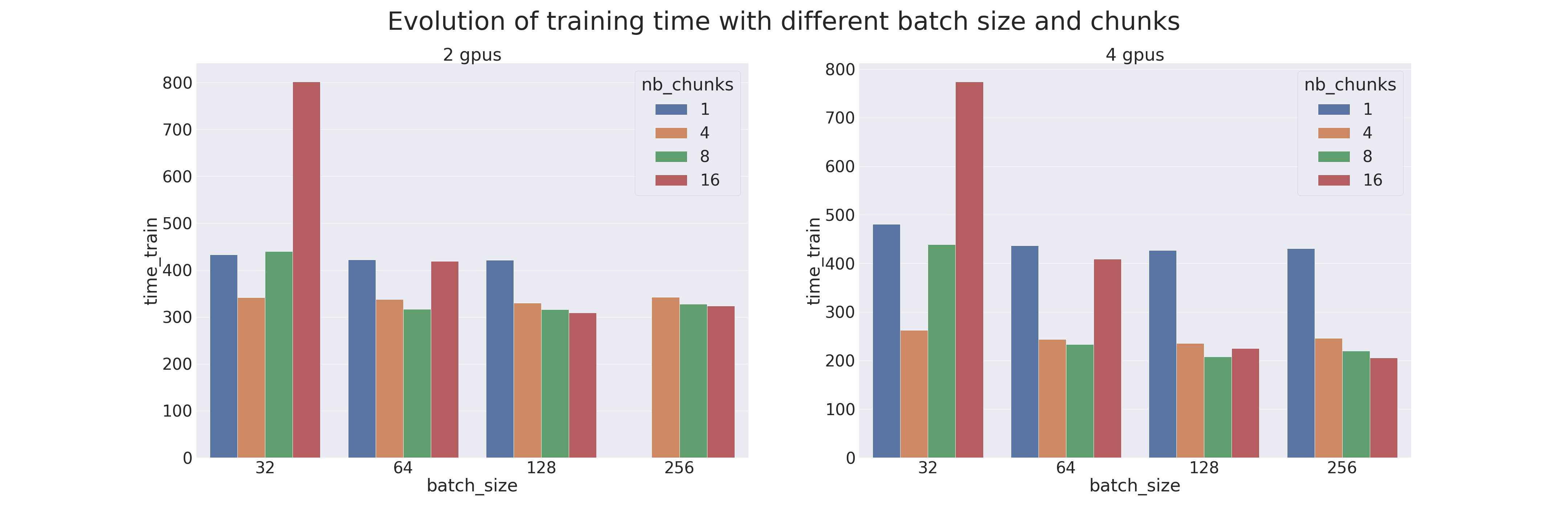
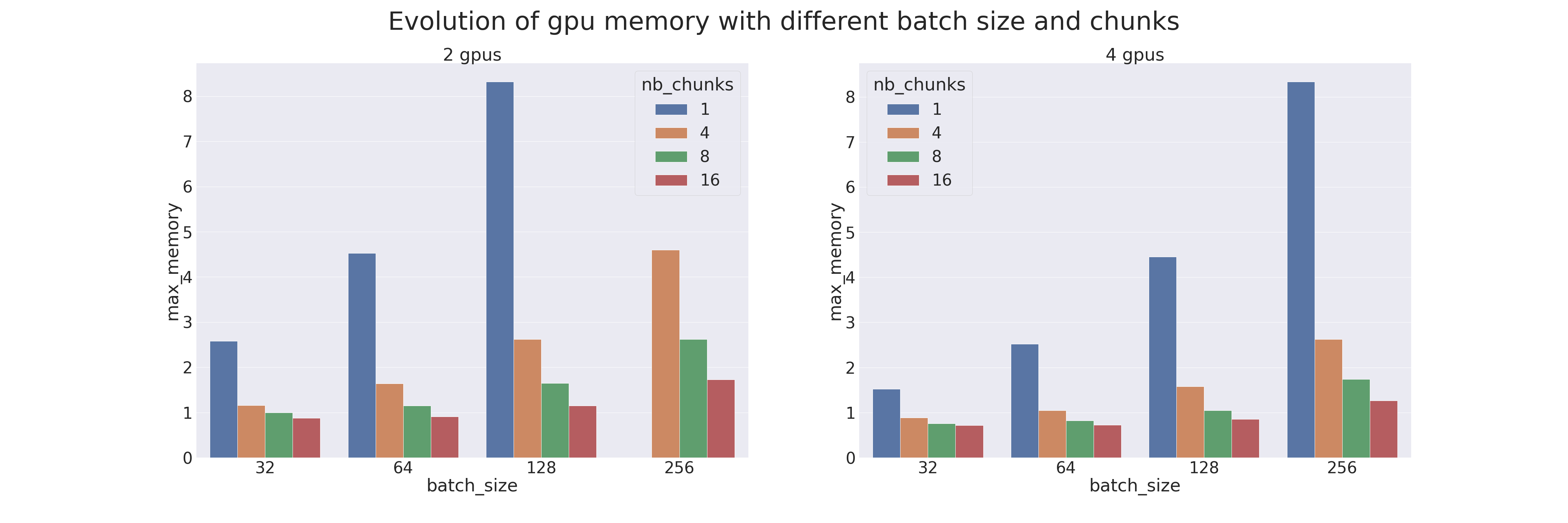
Résultats du bench
On remarque que le Pipeline Parallelism est toujours plus performant (en temps d’exécution et en mémoire) que le parallélisme de modèle lorsque le bon chunk est trouvé. Il faudra donc faire attention à bien accorder le nombre de chunks avec la taille du batch. Attention, le gain en mémoire est dû au gradient checkpointing qui est appliqué par défaut sur les modèles Pipe.
Pour aller plus loin
Scripts exemples
Des scripts exemples, adaptés à Jean-Zay, pour l'utilisation des librairies PEFT, Deepspeed et accelerate sont disponibles sur le dépôt plm4all. Ces scripts permettent une utilisation pour de l'inférence ou du fine-tuning de modèles. Ils ont pour vocation à servir de base pour l'implémentation des différentes librairies.
Autres ressources
-
Utiliser Deepspeed, la librairie d'optimisation Pytorch pour gros modèles
- Accélération optimale de l'apprentissage et économie de mémoire
- ZeRO, ZeRO Offload, ZeRO Infinity
- Activation checkpointing (équivalent au Gradient Checkpointing)
- Optimiseurs
-
Utiliser Pytorch Lightning, la simplification Pytorch pour la recherche en IA de haute performance
- Simplification et bonnes pratiques
- Sharded training (équivalent à ZeRO)
- Parallèlisme de modèle
- Plugin Deepspeed
- Profiler
-
Lire le guide Tensorflow sur l'optimisation des performances GPU
-
Lire le guide NVIDIA sur l'optimisation des performances GPU
-
La formation Deep learning Optimisé sur Jean-Zay (DLOJZ) proposée par l'IDRIS couvre, parmi d'autres thématiques, la parallélisation de l’entraînement, y compris le parallélisme de modèle. Plus d’informations sont disponibles ici.