

Table des matières
Performance tests of a Deep Learning training with and without Singularity containerisation
Benchmark goal
Containers are increasingly popular tools for their easy deployment on all types of machines. However, we can raise a question about their performance. The goal of this benchmark is to analyze the performance of a GPU-distributed learning algorithm with and without containerisation.
Test environment
The learning algorithm used is Megatron, a transformer developed by NVIDIA. It was executed on different numbers of GPUs to see the execution time difference between a code launched directly on the machine and when it is executed via a container. The tests without container were executed using the Module command. The module used is pytorch-gpu/py3/1.8.1.
The Slurm submission script used for an execution without container is the following (for execution on 16 GPUs on eight-gpu nodes):
#!/bin/sh #SBATCH --partition=gpu_p2 # use nodes with 24 CPUs and 8 GPUs #SBATCH --hint=nomultithread #SBATCH --time=01:00:00 #SBATCH --account=<my_project>@v100 # <my_project> is the value of IDRPROJ (echo $IDRPROJ) #SBATCH --job-name=megatron_16_GPU #SBATCH --nodes=2 # 2 nodes reserved #SBATCH --cpus-per-task=3 # 3 cores per process #SBATCH --ntasks-per-node=8 # 8 processes per node #SBATCH --gres=gpu:8 # 8 GPUs per node #SBATCH --output=./resultsAll/Megatron_%j_16_GPU.out #SBATCH --error=./resultsAll/Megatron_%j_16_GPU.err # go into the submission directory cd ${SLURM_SUBMIT_DIR} # cleans out modules loaded in interactive and inherited by default module purge module load pytorch-gpu/py3/1.8.1 ## launch script on every node set -x time srun python ./Megatron-LM/tasks/main.py --task IMDB --train-data /gpfswork/idris/sos/ssos024/Bench_Singularity/megatron_1B/imdb/dataset_train.csv --valid-data /gpfswork/idris/sos/ssos024/Bench_Singularity/megatron_1B/imdb/dataset_val.csv --tokenizer-type BertWordPieceLowerCase --vocab-file bert-large-uncased-vocab.txt --epochs 1 --tensor-model-parallel-size 1 --pipeline-model-parallel-size 1 --num-layers 24 --hidden-size 1024 --num-attention-heads 16 --micro-batch-size 8 --checkpoint-activations --lr 5.0e-5 --lr-decay-style linear --lr-warmup-fraction 0.065 --seq-length 512 --max-position-embeddings 512 --save-interval 500000 --save-interval 500 --log-interval 1 --eval-interval 1000 --eval-iters 50 --weight-decay 1.0e-1 --distributed-backend nccl --fp16
Tests with containers were carried out with the Singularity containerisation tool available via the module command on Jean Zay. The container used is a Pytorch Docker provided by NVIDIA.
A Docker image can be converted into a Singularity image using the following command, executed on the prepost partition (with ssh jean-zay-pp because the front-ends have a memory limit which prevents the conversion from going to term):
$ singularity build image_pytorch_singularity.sif docker:nvcr.io/nvidia/pytorch:21.03-py3
The Slurm submission script used for an execution with container is the following (for execution on16 GPUs on eight-gpu nodes) :
#!/bin/sh #SBATCH --partition=gpu_p2 # use nodes with 24 CPUs and 8 GPUs #SBATCH --hint=nomultithread #SBATCH --time=01:00:00 #SBATCH --account=<my_project>@v100 # <my_project> is the value of IDRPROJ (echo $IDRPROJ) #SBATCH --job-name=megatron_16_GPU_Singularity #SBATCH --nodes=2 # 2 nodes reserved #SBATCH --cpus-per-task=3 # 3 cores per process #SBATCH --ntasks-per-node=8 # 8 processes per node #SBATCH --gres=gpu:8 # 8 GPUs per node #SBATCH --output=./resultsAll/Megatron_%j_16_GPU_Sing.out #SBATCH --error=./resultsAll/Megatron_%j_16_GPU_Sing.err # go into the submission directory cd ${SLURM_SUBMIT_DIR} # cleans out modules loaded in interactive and inherited by default module purge module load singularity ## launch script on every node set -x time srun --mpi=pmix singularity exec --nv \ --bind .:$HOME,$JOBSCRATCH:$JOBSCRATCH $SINGULARITY_ALLOWED_DIR/MegaSingularity.sif \ python ./Megatron-LM/tasks/main.py --task IMDB --train-data ./imdb/dataset_train.csv --valid-data ./imdb/dataset_val.csv --tokenizer-type BertWordPieceLowerCase --vocab-file bert-large-uncased-vocab.txt --epochs 1 --tensor-model-parallel-size 1 --pipeline-model-parallel-size 1 --num-layers 24 --hidden-size 1024 --num-attention-heads 16 --micro-batch-size 8 --checkpoint-activations --lr 5.0e-5 --lr-decay-style linear --lr-warmup-fraction 0.065 --seq-length 512 --max-position-embeddings 512 --save-interval 500000 --save-interval 500 --log-interval 1 --eval-interval 1000 --eval-iters 50 --weight-decay 1.0e-1 --distributed-backend nccl --fp16
Results obtained
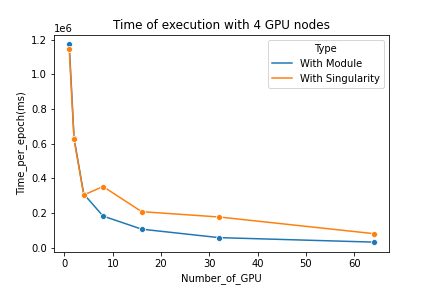
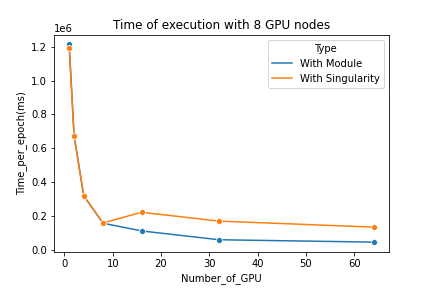
We see that as long as the code is executed on a single node there is no performance loss but when multiple nodes are used, executions via Singularity require more time than executions without a container. This performance loss stays relatively constant (about 100 000 ms) and is not proportional to the number of nodes used. We note that when we use a Singularity image, it is more efficient to use a single node rather than two as the time loss caused by the container is greater than the time gained by parallelisation even when using only two nodes.
Conclusion
We can conclude that code execution via a Singularity container involves significant performance loss on inter-node communications.
It is important to note that our modules are optimized on Jean Zay, contrary to the container images, which can explain the performance difference in the GPU node interconnections.