

Table des matières
Results of MgKOH bench for VASP
Times are given in s and energies in eV.
Column names
- nodes : number od nodes
- ncore : value of NCORE in INCAR file
- nsim : value of NSIM in INCAR file
- lplane : value of LPLANE in INCAR
- ntasks : number of MPI tasks per node
- nthreads : number of threads per MPI task
- ngpus : number of GPU per node used
- time : elapsed time of the job
- loop_time_avg : mean time taken for an electonic step
Best results
CPUs:
| nodes | ncore | nsim | lplane | ntasks | nthreads | ngpus | time | loop_time_avg |
|---|---|---|---|---|---|---|---|---|
| 1 | 40 | 16 | .TRUE. | 40 | 1 | 0 | 326.321 | 20.702 |
| 2 | 40 | 16 | .TRUE. | 40 | 1 | 0 | 207.496 | 12.376 |
| 4 | 40 | 16 | .TRUE. | 40 | 1 | 0 | 149.167 | 8.233 |
| 8 | 40 | 16 | .TRUE. | 40 | 1 | 0 | 132.685 | 6.867 |
| 16 | 40 | 16 | .TRUE. | 40 | 1 | 0 | 154.08 | 8.219 |
GPUs:
| nodes | ncore | nsim | lplane | ntasks | nthreads | ngpus | time | loop_time_avg |
|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 16 | .FALSE. | 2 | 5 | 1 | 374.243 | 23.157 |
| 1 | 1 | 16 | .FALSE. | 4 | 5 | 2 | 232.199 | 13.830 |
| 1 | 1 | 8 | .FALSE. | 8 | 5 | 4 | 183.041 | 10.584 |
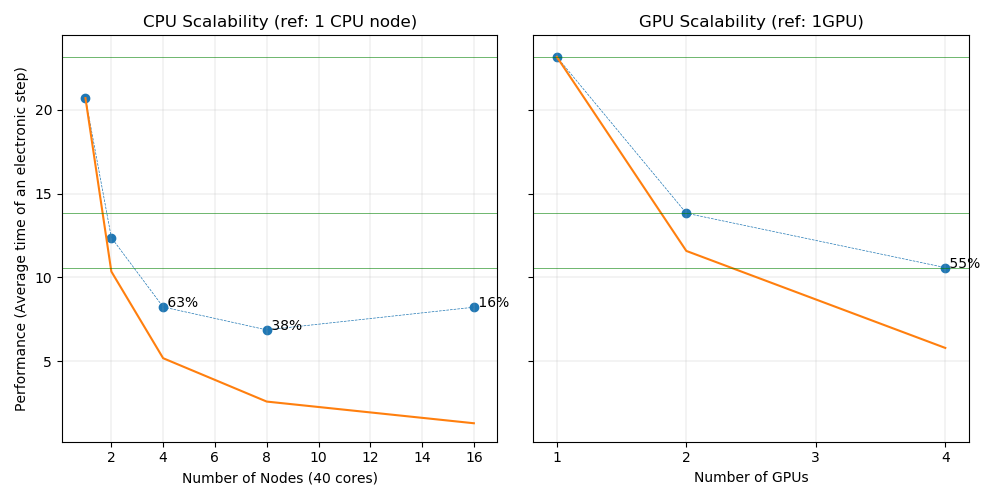
The effiency is displayed only if it is below 80%.
Summary
Here the use of one GPU is almost as good as using a complete (40 cores) CPU node. To reach this performance we need to overload the GPU with 10 tasks. Please note that this is only possible is the memory requirement is low enough.
In the GPU case LPLANE has no effect whereas for CPU it gives better results if set to .TRUE. .
The ideal value of NSIM is 16 in this case. It controls the number of bandes optimized simultaneously when a RMM-DIIS step.
Activating MPS gives a slightly better performance.