

Jean Zay : Outils de profilage d'applications TensorFlow et PyTorch
Le profilage est une étape indispensable de l'optimisation d'un code. Son but est de cibler les étapes d'exécution les plus coûteuses en temps ou en mémoire, et de visualiser la répartition de la charge de travail entre GPU et CPU.
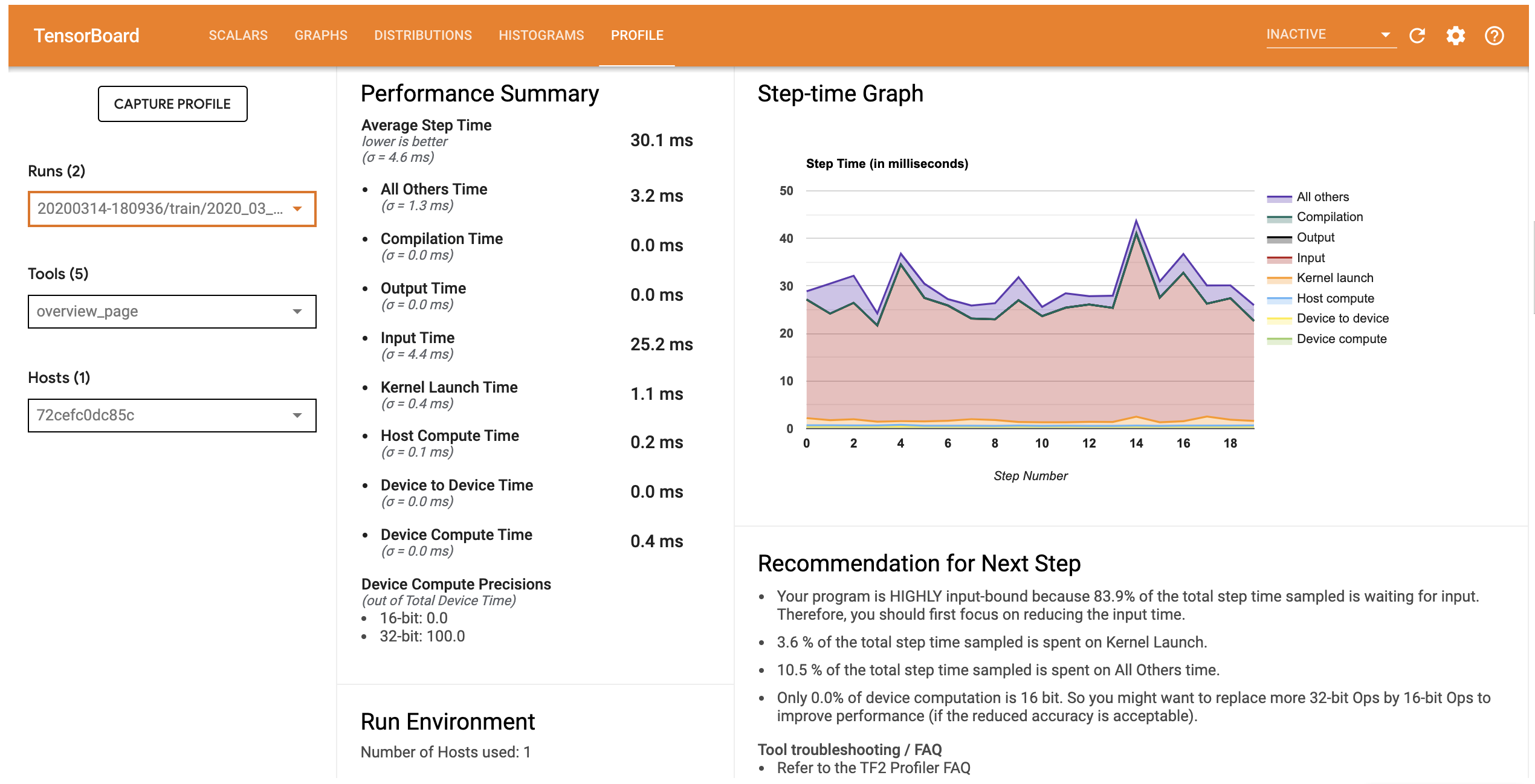
Profiler une exécution est une opération très gourmande en temps. Cette étude se fait donc en général sur quelques itérations de votre entraînement. La création des logs se fait a posteriori, à la fin du travail. Il n'est pas possible de visualiser le profilage pendant son exécution. La visualisation des logs peut donc se faire indifféremment sur Jean Zay ou sur votre propre machine locale (parfois cela sera plus facile de le faire sur votre propre machine !).
Nvidia aussi, fournit un profiler spécifique pour le Deep Learning baptisé DLProf. Couplé avec Nsight son outil de debug de Kernel GPU, il permet de recueillir un ensemble d'informations extrêmement complet. Cependant la mise en œuvre peut s'avérer un peu complexe et ralentir fortement l'exécution du code.
Solutions de profilage avec Pytorch et TensorFlow
Les 2 librairies proposent des solutions de pofilage. Pour l'instant nous documentons:
- avec Pytorch:
- avec TensorFlow:
Remarque: DLProf avec TensorFlow ne marche pas actuellement.
Chacun de ces outils de profilage sont capables de tracer l'activité du GPU.
Le tableau comparatif suivant liste les capacités et possibilités de chacuns de ces outils.
| Profiler | Ease-of-use | Slow down code | Overview | Recom-menda-tions | Trace view | Multi GPU Dist. View | Memory profile | Kernel View | Operator View | Input View | Tensor Core efficiency view |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Pytorch TensorBoard | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | . | ✓ |
| Pytorch Natif | ✗ | ✓ | ✗ | . | ✓ | . | ✓ | . | . | . | . |
| DLProf + Pytorch | ✗ | ✗ | ✓ | ✓ | ✓ | ✗ | . | ✓ | ✓ | . | ✓ |
| TensorFlow TensorBoard | ✓ | ✓ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | . | ✓ | . |
avec:
- ✓ : fonctionnalité présente et sentiment positif
- ✗ : fonctionnalité présente et sentiment négatif (difficulté ou version actuelle limitée)
- . : fonctionnalité absente