

Table des matières
Accelerating calculations with the use of Tensor Cores
Tensor Cores
All the calculation units are designed to take charge of arithmetic and logical operations. Nevertheless, some of these operations require more elementary calculation than others. The multiplication of matrices/tensors and convolution are part of these computationally-intensive operations. These operations are also very often used in AI.
The simple multiplication of two 4×4 matrices requires 64 multiplication operations and 48 addition operations. Moreover, calculation complexity of this type of operation increases very rapidly as the size and dimensions of the matrice increase 1).
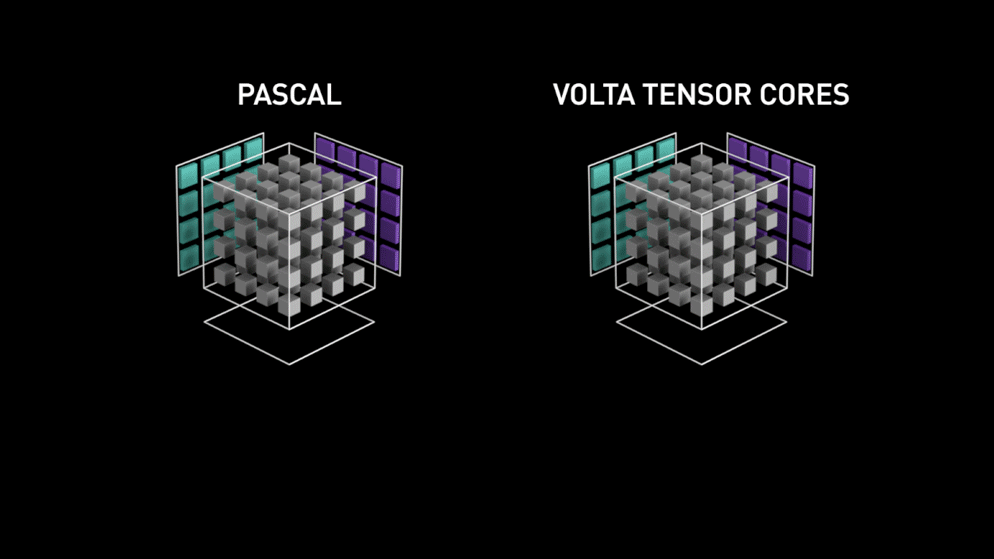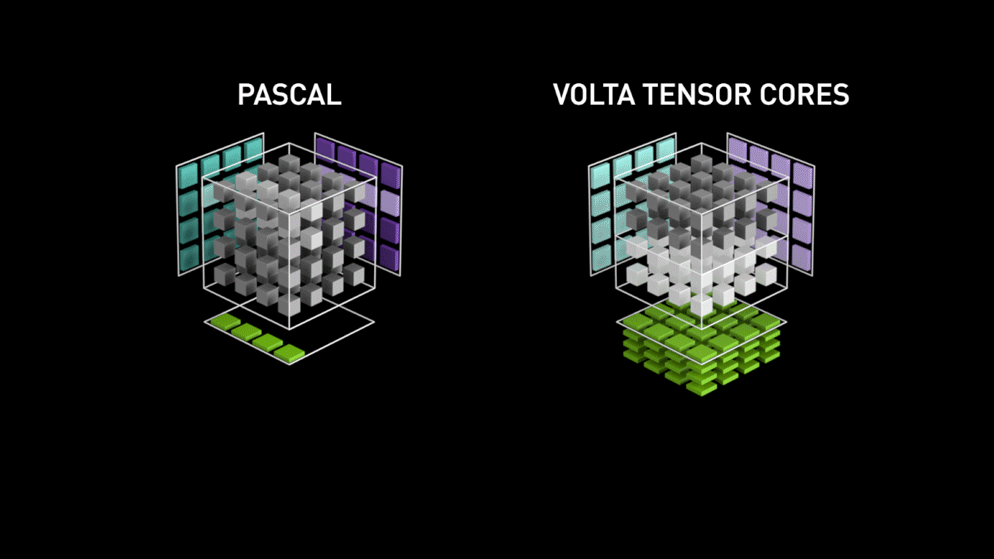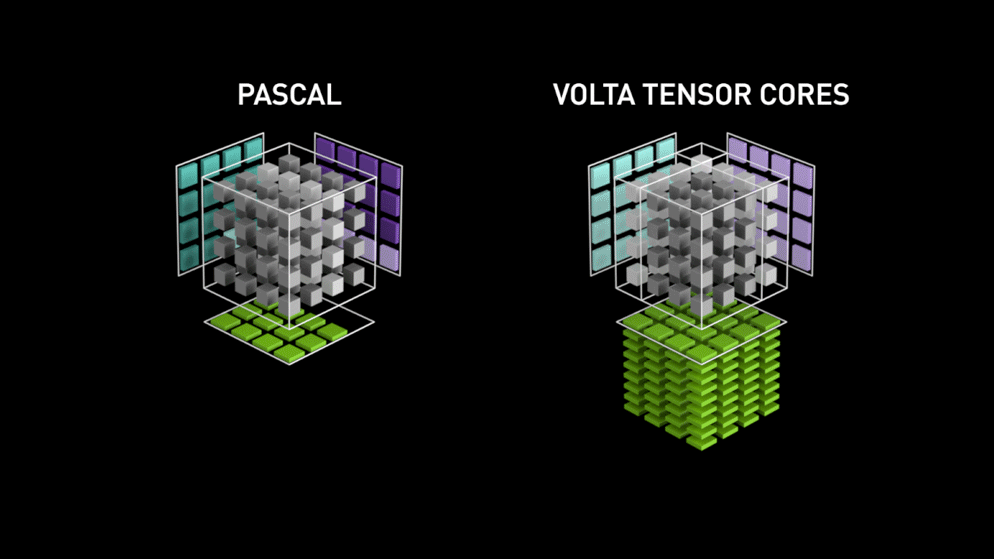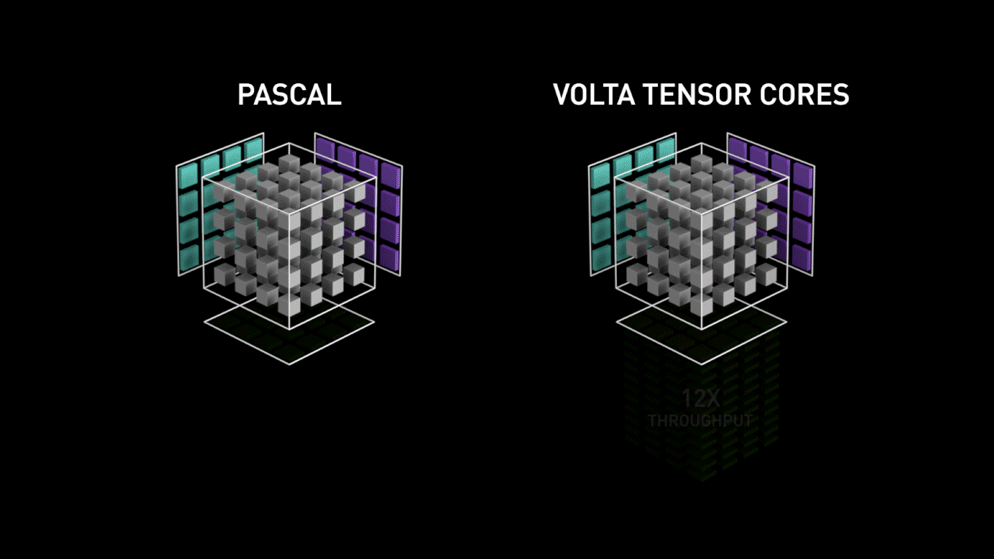
To address this problem, NVIDIA (since its Volta architecture) proposes a specitic calculation unit: The Tensor Core
This is a specialised calculation unit (of hardware) in the tensor multiplication. Where CUDA cores need to carry out a series of elementary operations (multiplications and additions), the tensor cores realise the same thing all at once. Therefore, the time gain can be extremely important depending on the precision being employed and the GPU used. We are speaking of a gain between 2x and 3x on the majority of Deep Learning models.
Use Tensor Cores and benefit from the acceleration
As indicated in the preceding paragraph, using tensor cores for multiplication operations results in a very important performance gain. This is, therefore, a fundamental step for those who wish to optimise their learning times (or inferences).
Jean Zay has NVIDIA V100 and A100 GPUs. These two models both have tensor cores. However, the usage and implementation differ between the two models. The tensor cores generally function with lower precisions (hardware criterion). The lower the precision, the more the calculation will be executed rapidly. The available precisions depend on the GPU architecture and model.
Some examples of precision available on the tensor cores of Jean Zay GPUs:
| GPU | Tensor precision | Computing power |
|---|---|---|
| V100 | FP16 | 112 TFLOPS |
| A100 | FP64 Tensor Core | 19.5 TFLOPS |
| A100 | Tensor Float 32 (TF32) | 156 TFLOPS |
| A100 | FP16 Tensor Core | 312 TFLOPS |
| A100 | INT8 Tensor Core | 624 TOPS |
Utilisation on the NVIDIA V100 GPUs :
The NVIDIA V100 (Volta) GPUs represent the largest portion of the GPUs available on Jean Zay. Their architecture is the first to implement the Tensor Cores (640 tensor cores). Due to their hardware design, these tensor cores only realise calculations with a Float16 precision. Most of the AI models are in Float32. If you wish to benefit from the acceleration enabled by the tensor cores, it is necessary to reduce the precision of your variables 2). There are two possible ways of doing this:
- Put all of the elements of your model in Float16.
- Use AMP / mixed precision ⇒ Highly recommended.
Utilisation on the NVIDIA A100 GPUs:
The latest extension of Jean Zay provides NVIDIA A100 GPUs. These much more recent and efficient GPUs offer the third generation of tensor cores (432 tensor cores). They enable using tensor cores with the currently used precisions and also the new precisions. The A100s can directly manage the usage of their tensor cores. Therefore, without a supplementary code line, the hardware is able to intelligently convert certains variables in order to carry out calculations on tensor cores. We benefit from the acceleration without making any effort.
Important: The architecture has its limits. If you observe an automatic usage of the tensor cores, this will be relatively weak. .
Comment: AMP is still recommended. It enables a greater usage of tensor cores compared to a usage without instructions. Moreover, AMP has other advantages, particularly concerning the memory usage.