

Table des matières
Accélération des calculs avec l'usage des Tensor Cores
Les Tensor Cores
Toutes les unités de calcul sont conçues pour prendre en charge des opérations arithmétiques et logiques. Certaines de ces opérations demandent néanmoins plus de calcul élémentaire que d'autres. La multiplication de matrices/tenseurs et la convolution font partie de ces opérations très gourmandes en calcul. Il se trouve qu'elles sont aussi très souvent utilisées en IA.
La simple multiplication de 2 matrices 4×4 va nécessiter 64 opérations de multiplication et 48 opérations d'addition. De plus, la complexité de calcul de ce type d'opération augmente très rapidement à mesure que la taille et les dimensions de la matrice augmentent1).
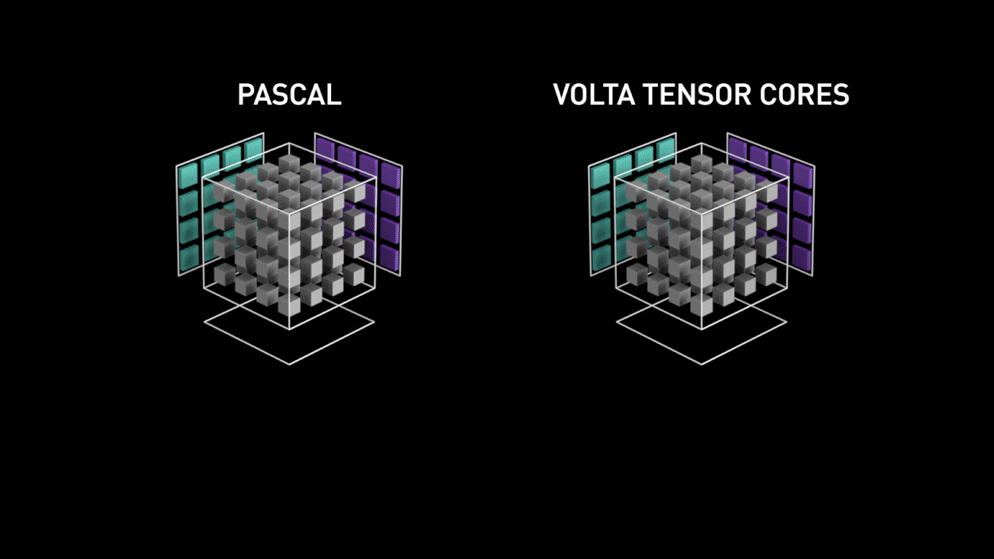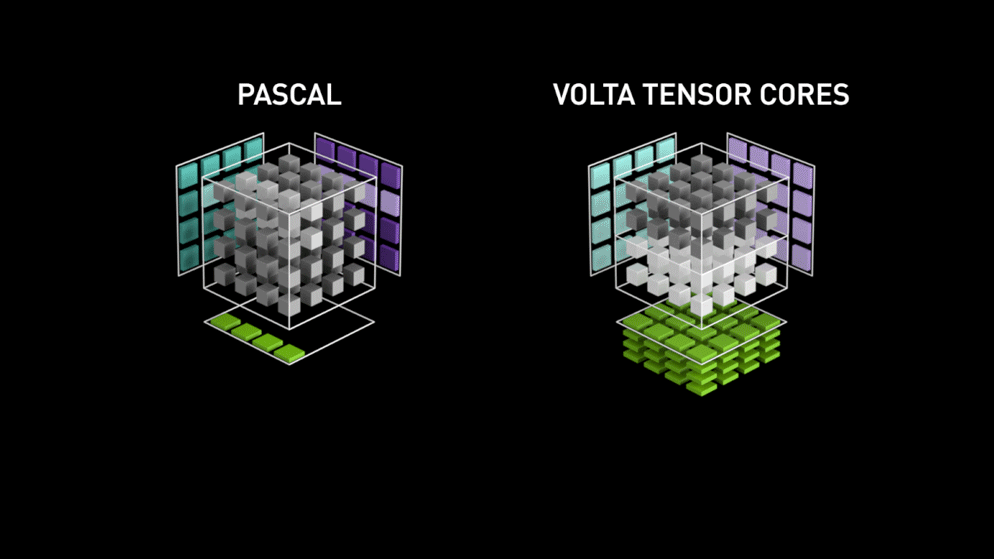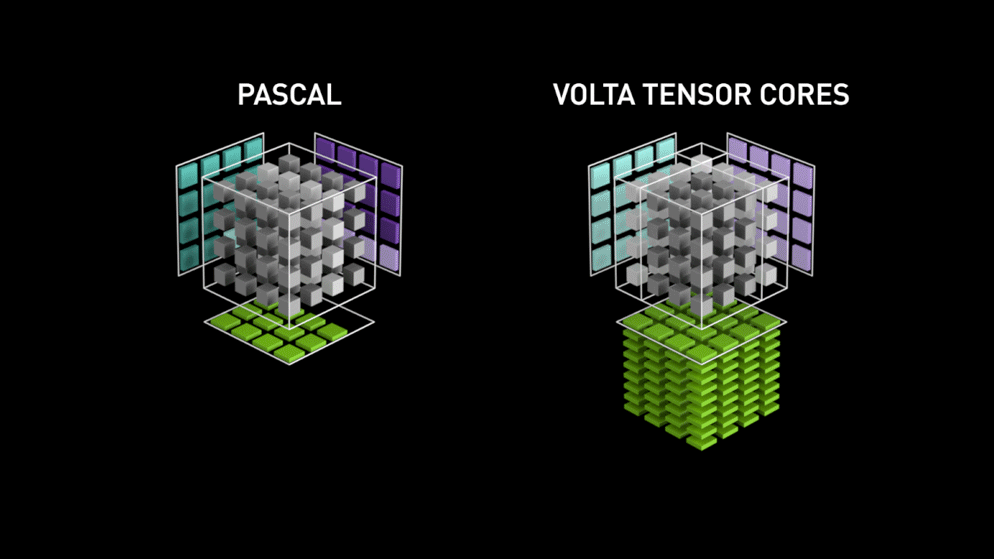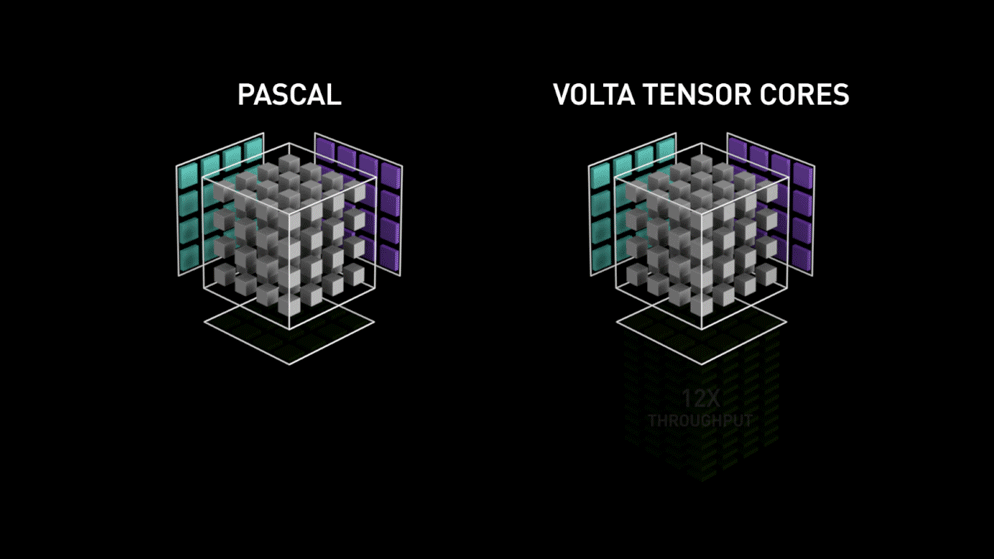
Pour répondre à ce problème, NVIDIA propose depuis son architecture Volta une unité de calcul spécifique : Le Tensor Core
C'est une unité de calcul spécialisée (de façon matérielle) dans la multiplication de tenseur. Là où les CUDA cores doivent réaliser une suite d'opérations élémentaires (multiplications et additions), les tensor cores réalisent la même chose en une seule fois. Le gain de temps peut alors être extrêmement important suivant la précision employée et le GPU utilisé. On parle d'un gain compris entre x2 et x3 sur la grande majorité des modèles de Deep Learning.
Utiliser et profiter de l'accélération des Tensor cores
Comme indiqué dans le paragraphe précédent, l'usage des tensor cores pour les opérations de multiplication permet un gain de performance très important. C'est donc une étape obligée pour ceux qui souhaitent optimiser leurs temps d'apprentissages (ou inférences).
Jean-Zay dispose de GPU NVIDIA V100 et A100. Ces deux modèles disposent de tensor core. L'usage ainsi que l'implémentation diffèrent néanmoins entre les deux modèles.
Les tensor cores fonctionnent généralement avec des précisions plus faibles (critère matériel). Plus la précision est faible, plus le calcul va s'exécuter rapidement. Les précisions disponibles dépendent de l'architecture et du modèle de GPU.
Quelques exemples de précision disponibles sur les tensor cores des GPU de Jean Zay :
| GPU | Précision du tenseur | Puissance de calcul |
|---|---|---|
| V100 | FP16 | 112 TFLOPS |
| A100 | FP64 Tensor Core | 19.5 TFLOPS |
| A100 | Tensor Float 32 (TF32) | 156 TFLOPS |
| A100 | FP16 Tensor Core | 312 TFLOPS |
| A100 | INT8 Tensor Core | 624 TOPS |
Utilisation sur les GPU NVIDIA V100 :
Les GPU NVIDIA V100 (Volta) représentent la plus grande partie des GPU disponibles sur Jean-Zay. Leur architecture est la première à implémenter les Tensor Cores (640 tensor cores). En raison de leur conception matérielle, ces tensor cores réalisent des calculs uniquement avec une précision en Float16. La plupart des modèles d'IA sont en Float32. Si l'on souhaite profiter de l'accélération permise par les tensor cores, il faut donc réduire la précision de nos variables 2). Pour ce faire, il y a deux solutions possibles :
- Mettre l'ensemble des éléments de notre modèle en Float16
- Mettre en place l'AMP / la précision mixe ⇒ Très recommandé
Utilisation sur les GPU NVIDIA A100 :
La dernière extension de Jean-Zay dispose de GPU NVIDIA A100. Ces GPU beaucoup plus récents et performants disposent de la 3ème génération de tensor core (432 tensor cores). Ils permettent l'usage des tensor cores avec les précisions couramment utilisées mais aussi avec des nouvelles. Les A100 peuvent gérer eux même l'usage de leurs tensor cores. Ainsi, sans ligne de code supplémentaire, le matériel va pouvoir convertir intelligemment certaines variables afin de réaliser des calculs sur tensor cores. On profite de l'accélération sans effort.
Attention : l'architecture a des limites. Si l'on constate un usage automatique des tensor cores celui-ci est relativement faible.
Remarque : l'AMP est toujours recommandée. Elle permet une utilisation plus importante des tensor cores par rapport à un usage sans indication. De plus l'AMP a d'autres avantages notamment concernant l'usage de la mémoire.