

Table des matières
Utiliser l'AMP (Précision Mixte) pour optimiser la mémoire et accélérer des calculs
Principe de fonctionnement
Le terme de précision fait référence ici à la manière de stocker des variables réelles en mémoire. La plupart du temps, les réels sont stockés sur 32 bits. On les appelle des réels à virgule flottante 32 bits, ou float32, et on parle de simple précision. Les réels peuvent également être stockés sur 64 ou 16 bits, selon le nombre de chiffres significatifs souhaité. On parle respectivement de float64 ou double précision, et de float16 ou semi précision. Les frameworks TensorFlow et PyTorch utilisent par défaut la simple précision, mais il est possible d'exploiter la semi précision pour optimiser l'étape d'apprentissage.
On parle de précision mixte quand on fait cohabiter plusieurs précisions dans le même modèle lors des étapes de propagation et de rétro-propagation. Autrement dit, on réduit la précision de certaines variables du modèle pendant certaines étapes de l’entraînement.
Il a été montré empiriquement que, même en réduisant la précision de certaines variables, on obtient un apprentissage de modèle équivalent en performance (loss, accuracy) tant que les variables “sensibles” conservent la précision float32 par défaut, et ce pour tous les “grands types” de modèles actuels. Dans les frameworks TensorFlow et PyTorch, le caractère “sensible” des variables est déterminé automatiquement grâce à la fonctionnalité Automatic Mixed Precision, ou AMP. La précision mixte est une technique d'optimisation de l'apprentissage. À la fin de celui-ci, le modèle entraîné est reconverti en float32, sa précision initiale.
Sur Jean Zay, l'usage de l'AMP permet d'utiliser les Tensor Cores des GPU NVIDIA V100. L'usage de l'AMP va donc permettre d'effectuer plus efficacement les opérations de calcul tout en gardant un modèle équivalent.
Remarque : Jean Zay dispose aussi de GPU NVIDIA A100 dont les Tensor cores peuvent utiliser des FP16 mais aussi des TF32 (tensor float, équivalent au float32), dans ce cas on peut choisir d'utiliser ou non une précision élevée ou mixe tout en profitant des Tensor cores. Evidement, l'usage d'une précision plus faible permet toujours de gagner un peu plus en vitesse.
Intérêts et contraintes de la précision mixte
Voici quelques avantages à exploiter la précision mixte :
- Concernant la mémoire :
- Le modèle occupe moins de place en mémoire puisqu'on divise par deux la taille de certaines variables. 1)
- Les variables étant plus rapides à transférer en mémoire, la bande passante est moins sollicitée.
- Concernant les calculs :
- Les opérations sont grandement accélérées (de l'ordre de 2x ou 3x) grâce à l'usage de Tensor cores. On réduit le temps d'apprentissage.
Parmi les exemples classiques d'utilisation, la précision mixe est utilisée pour:
- réduire la taille en mémoire d'un modèle (qui dépasserai la taille mémoire du GPU)
- réduire le temps d'apprentissage d'un modèle (comme les réseaux convolutionnels de grande taille)
- doubler la taille du batch
- augmenter le nombre d'epoch
Il y a peu de contrainte à utiliser l'AMP. On peut noter une très légère baisse de la précision du modèle entraîné (qui est pleinement compensée par le gain en mémoire et en calcul) ainsi que le rajout de quelques lignes de code.
Efficacité de l'AMP sur Jean Zay
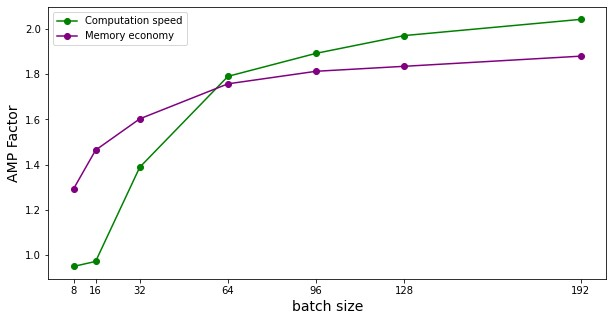
Les figures suivantes illustrent les gains en mémoire et en temps de calcul fournis par l'usage de la précision mixte. Ces résultats ont été mesurés sur Jean Zay pour l'entraînement d'un modèle Resnet50 sur CIFAR et exécuté en mono-GPU. (1er benchmark avec Resnet101)
{kind=link}
PyTorch mono-GPU V100 :
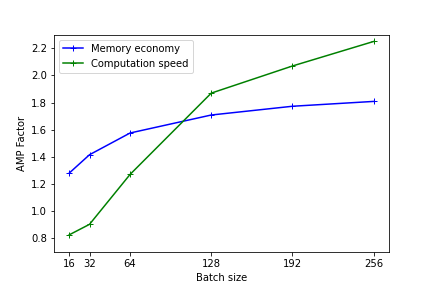
PyTorch mono-GPU A100 :
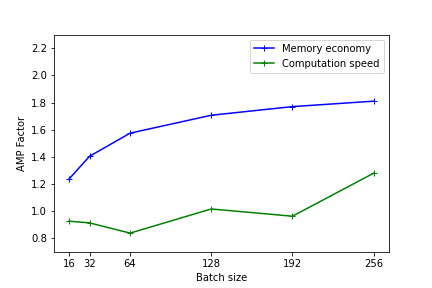
Tensorflow mono-GPU V100 :
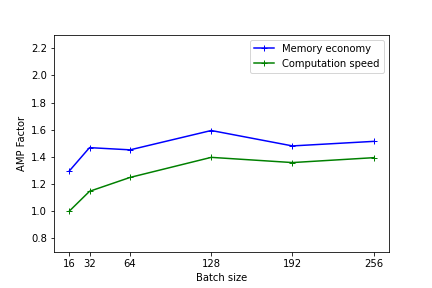
Tensorflow mono-GPU A100 :
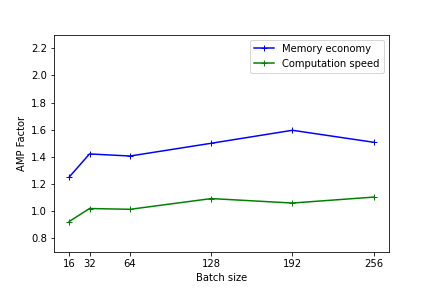
Plus le modèle est lourd (en terme de mémoire et d'opérations) plus l'usage de la précision mixte sera efficace. Toutefois, même pour des modèles légers, il existe un gain de performance observable.
Sur les plus petits modèles, l'usage de l'AMP n'a pas d’intérêt. En effet le temps de conversion des variables peut être plus important que le gain réalisé avec l'usage des Tensor Cores.
Les performances sont meilleures quand les dimensions du modèle (batch size, taille d'image, couches embedded, couches denses) sont des multiples de 8, en raison des spécificités matérielles des Tensor cores comme documenté sur le site Nvidia .
Remarque : Ces tests permettent de se faire une idée de l'efficacité de l'AMP. Les résultats peuvent être différents avec d'autres type et tailles de modèle. Implémenter l'AMP reste le seul moyen de connaître le gain réel sur votre modèle précis.
En PyTorch
Depuis la version 1.6, PyTorch inclut des fonctions pour l'AMP (se référer aux exemples de la page Pytorch).
Pour mettre en place la précision mixte et le Loss Scaling, il faut ajouter quelques lignes :
from torch.cuda.amp import autocast, GradScaler scaler = GradScaler() for epoch in epochs: for input, target in data: optimizer.zero_grad() with autocast(): output = model(input) loss = loss_fn(output, target) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update()
Attention: Avant la version 1.11; Dans le cas d'un code distribué en mono-processus, il faut spécifier l'usage de l'autocast avant l'étape de forwarding au sein même de la définition du model (voir le fix de la page Pytorch). On préférera à cette solution l'usage d'un processus par GPU tel qu'il est recommandé par distributeddataparallel
Remarque: NVIDIA Apex propose aussi l'AMP mais cette solution est maintenant obsolète et déconseillée.
En TensorFlow
Depuis la version 2.4, TensorFlow inclut une librairie dédiée à la mixed precision :
from tensorflow.keras import mixed_precision
Cette librairie permet d'instancier la précision mixte dans le backend de TensorFlow. L'instruction est la suivante :
mixed_precision.set_global_policy('mixed_float16')
Attention : Si vous utilisez une strategie de distribution tf.distribute.MultiWorkerMirroredStrategy, l'instruction mixed_precision.set_global_policy('mixed_float16') devra être positionnée à l'intérieur du contexte with strategy.scope().
On indique ainsi à TensorFlow de décider, à la création de chaque variable, quelle précision utiliser selon la politique implémentée dans la librairie. L'implémentation du Loss Scaling est automatique lorsque l'on utilise keras.
Si vous utilisez une boucle d'apprentissage personnalisée avec un GradientTape, il faut explicitement appliquer le Loss Scaling après la création de l'optimiseur et les étapes de la Scaled Loss (se référer à la page du guide TensorFlow).
Loss Scaling
Il est important de comprendre l'influence de la conversion en float16 de certaines variables du modèle et de ne pas oublier d'implémenter la technique de Loss Scaling lorsque l'on utilise la précision mixte.
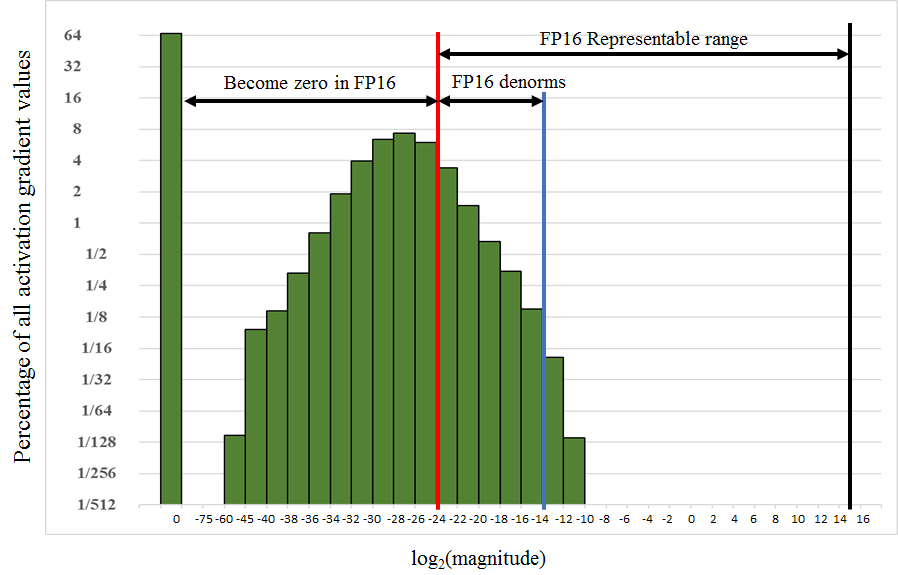
En effet, la plage des valeurs représentables en précision float16 s'étend sur l'intervalle [2-24,215]. Or, comme on le voit sur la figure ci-contre, dans certains modèles, les valeurs des gradients sont bien inférieures au moment de la mise à jour des poids. Elles se trouvent ainsi en dehors de la zone représentable en précision float16 et sont réduites à une valeur nulle. Si l'on ne fait rien, les calculs risquent d'être faussés alors que la plage de valeurs représentables en float16 restera en grande partie inexploitée.
Pour éviter ce problème, on utilise une technique appelée Loss Scaling. Lors des itérations d'apprentissage, on multiplie la Loss d’entraînement par un facteur S pour déplacer les variables vers des valeurs plus élevées, représentables en float16. Il faudra ensuite les corriger avant la mise à jour des poids du modèle, en divisant les gradients de poids par le même facteur S. On rétablira ainsi les vraies valeurs de gradients.
Pour simplifier ce processus, il existe des solutions dans les frameworks TensorFlow et PyTorch pour mettre le Loss scaling en place.
1)
La mémoire occupée est généralement plus faible mais pas dans tous les cas. En effet certaines variables sont sauvegardés à la fois en float16 et float32 , ce rajout de donnée n'est alors pas forcément compensé par la réduction en float16 des autres variables.